最近Facebookにばかり書いているのですが, 今回は数式と図が入っているので,
こちらで。
ほぼ10年前の
ホットケーキ分割
の続き(?)として, 自分用メモ。
ゴールデンウィークなので, 湯河原の喫茶店
WEST本店
でチョコモンブランケーキを1つ頼んで奥様と二人で分けようとして, ふと思った。
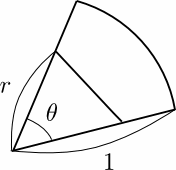
ケーキを二つに分けるとき, 放射状に分けると薄くなってしまって扱いづらいので,
普通に横に切って二つに分けたくなります。ケーキが二等辺三角形ならば, 面積の比を
1:1にするためにはケーキの円の半径を1として1/√2の所で切ればいいわけですが,
図のように実際はケーキは円のため弧の部分が外に出ているので,
それでは実際に1/2にするためにはどこで切ればいいのでしょう, という問題。
この答えは計算すると簡単で, 図のようにケーキの中心角をθにとると, 半径を1,
切る場所をrとして, 切った三角形の面積は
r・rsinθ・1/2 = 1/2r2sinθ.
一方で円弧の面積は π・1^2・θ/(2π)=θ/2 なので, この半分が上に等しいとおくと
1/2r
2sinθ = θ/4. これを解くと
r = √θ/(2sinθ) = 1/√2・√(θ/sinθ)
になります。
つまり, 円弧を考えない場合の解 1/√2 に対して, √(θ/sinθ) というファクターが掛かっている, ということ。よく知られているようにθ〜0のとき
θ〜sinθなので, この補正項の値はほぼ1で, θが大きくなって例えばケーキの普通の
最大角であるπ/4くらいになると, 計算すると 1.054 くらいになる模様。
というわけで, 面積を1/2にするには普通は三角形では1/√2=70.7%の所で切ればいい
ですが, ショートケーキの場合は上の式で, 45°のケーキでは 74.52%, ほぼ3/4の所
で切らなければならないということのようです。
 クリーム好き
クリーム好き
上の話を聞いた奥様曰く, ケーキが好きな人はクリームが好きなので, クリームが
平等に分配される分割が必要なんじゃない? ということで, 以下補足。
ケーキの高さをhとすると, クリームはショートケーキの枠の部分にも付いているので,
クリーム全体の量は(深さは無視できるので)
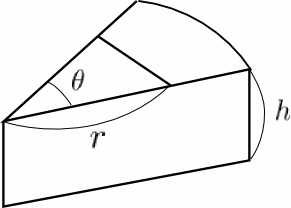
θ/2 + 2π・1・θ/(2π)・h = θ/2+θh.
この半分が1/2r^2sinθに等しいとおいて計算すると, rは
r = √θ/(2sinθ)・√(1+2h)
になるようです。当然 h=0 のときは後ろのファクターは1で, 典型的なh=0.5くらい
のときは, ファクターは √2 でrの値が1.41倍くらいになる計算。
..と, ここまで書いたところで, h=0.5のときにちょうど枠の部分のクリームと上の
クリームの量が同じになるので(意外!), h>=1/2ではrを幾つにするかという議論は
成り立たないことに気付きました。ちなみに h=1/3, θ=π/6の場合,
r=0.9341と, ほとんど縁ギリギリの値になるようです。
というわけで, 永年の疑問?の一つが解決したのでした。
やった!
CSJ(と新聞記事)からの, 単語の「女性度」の結果。
単純に中身に依存する語も混じっていますが, 結構女性らしい気がします。
とりあえず, 「青空フレーズ」も女性らしさの高い漫画のタイトルになるということが
わかりました。w
表明 4.6383
青空 4.5353
見渡す 4.5167
寒かっ 3.9486
放っ 3.8496
凄かっ 3.7123
フレーズ 3.6517
重み 3.6218
単なる 3.5859
満開 3.5602
くさく 3.5188
治し 3.5034
届く 3.3464
動員 3.3411
振り掛け 3.3402
たちまち 3.3228
広げる 3.3200
触る 3.2801
断わり 3.2613
立ち上がっ 3.2359
きらきら 3.2313
整える 3.1912
ちなみにこちらは男性度の高い単語。む, むさい。。
ビションフリーゼ 0.0695
輸出 0.0698
真理 0.0765
福沢 0.0805
ミート 0.0934
松下 0.1030
仲直り 0.1046
加藤 0.1047
整形 0.1049
僕 0.1053
霊感 0.1120
茅が崎 0.1120
果実 0.1128
包帯 0.1138
ニュージーランド 0.1147
オートレース 0.1157
干潟 0.1225
保全 0.1234
漫画 0.1248
死刑 0.1275
独自 0.1299
ハイテク 0.1332
NAACL/HLT 2009に出る予定の論文,
"Global Models of Document Structure Using Latent Permutations"
[pdf]
[code]
が面白そうだったので, 読んでみた。
若干仮定が強すぎたりする面はありますが, 興味深い話で,
理解を深めるためにこの場所を使って整理。
これは一言で言うと, 潜在トピックの表れる順序に一般化Mallows Modelを
仮定して文書構造を表現する, という話で, 実は自然言語処理一般に
有益な可能性がある話だと思う。
Mallows Modelが順序の確率分布だということは前から知っていたものの,
ランキングの研究をしているわけではないので,
自分にはとりあえず関係ないと思ってこれまでスルーしていた。
Barzilayのグループは以前から文書構造の研究をしていますが,
今回は新しい話で,
「潜在変数の表れる順番には一定の確率的なパターンがある」ことをモデル化している
ことになっている。
LDAのようなbag of wordsのモデルはトピックがバラバラになってしまうので,
トピックの順番を考慮する方法としては潜在トピックにHMMを仮定するHT-HMMなどが
あった
*1
ものの, HMMでは前後の局所的な繋がりだけしか見ないので, 文書全体として
前半にはこんな話が現れやすい, 最後にはこんな話題が出やすい, というような
全体的な文書構造はモデル化できない。
この話では, データを特定のドメイン(Wikipediaの記事など)に限った上で,
各パラグラフに一つの潜在トピックを割り当て,
*2
その順番に一定のパターンがあるというモデル化になっている。
一般化Mallows Model(GMM)は, あるcanonicalな順序から外れるほど確率が低くなる,
というような確率分布で, 潜在変数の場合にはラベリングは自由なので,
K個の潜在トピックのcanonicalな
順序を [1 2 .. K] としても一般性を失わない。(中には使われないトピックもある。)
*3
このとき, p = [2 1 4 .. K] のような順序の確率は, GMMに従うと
GMM(p|w) = exp(-Σ_j w_j v_j) / ψ(w)
と計算できる。ここで v_j はpの各要素がcanonicalな順序を破っている回数で,
GMMはケンドールの相関係数τを, 重みwを使って一般化したものになっている
ようだ。(以下知っている人は飛ばして下さい。)
MATLABで書くと, 下のようなコードになる。
function q = mallows(w,p)
% q = mallows(w,p)
% returns the probability of the generalized Mallows model.
% w : vector of weights
% p : permutation (canonical order = 1..n)
% $Id: mallows.m,v 1.1 2009/05/02 13:44:42 daichi Exp $
K = length(w);
if length(p) ~= K
error('dimensions of w and p must be equal.');
end
q = 1;
for i = 1:K
j = p(i);
if j < K
v(j) = sum(p(1:i) > j);
end
end
for j = 1:K-1
q = q * exp(-w(j)*v(j)) ...
* (1 - exp(-w(j))) / (1 - exp(-w(j)*(K-j+1)));
end
たとえば簡単な例として, canonical order [1 2 3 4] での各要素の重要性が
(起承転結のような感じで) w = [2.0 1.0 4.0 3.0] だったとき,
GMMに基づく確率は
| p | GMM(p|w) | GMM(p|w/2) | GMM(p|w/10) | 説明 |
|---|
| [1 2 3 4] | 0.5651 | 0.2873 | 0.0724 | canonicalな順番と同じ |
| [2 1 3 4] | 0.0765 | 0.1057 | 0.0592 | 重要でない前半を入れ替え |
| [3 2 1 4] | 0.0103 | 0.0236 | 0.0439 | 重要性の高い3番目を1番目と交換 |
| [4 3 2 1] | 0.000003 | 0.0007 | 0.0218
| 完全に逆 |
のようになる。
後ろの2つは, 重みを全体に1/2,1/10にした場合で, ディリクレ分布のように,
その場合は確率の集中が穏やかになる。
いま, 各文書のトピック毎のパラグラフが, ディリクレ分布からそれぞれサンプルした
多項分布から生起していると考えると, パラグラフの確率はPolya(DCM)分布になり,
ここに, そのパラグラフが隠れトピックtを持つ, 全体のGMMによる確率が掛かることで,
パラグラフの持つ隠れトピックをGibbsでサンプリングすることができる。
逆に各パラグラフの持つトピックがわかれば, GMMの事後分布は共役で同じ形になる
ので, 全体のGMMのパラメータwの事後分布が計算できてサンプルする, というのを
繰り返す模様。
文書全体が共通のトピック構造に従うとか, パラグラフ全体が同じ隠れトピックを持つ
とか, かなり制約が強いので, それ自体すぐに一般の文書集合に使えるというもの
ではないと思いますが, "GMMを隠れ変数に使う"という部分が目から鱗でした。
目に見える順番があるものにGMMを使うのはランキングの学習では普通で,
SMTで単語をリオーダーする場合の確率にも使えるようですが, 一般にトピックに限らず
隠れ変数の順番に一定の大域的構造があるということは普遍的に思えるので, 色々
使いどころがあるのではないか, と思ったのでした。
ちなみに, この結果, 昔(数年前)に知って全く意味不明だった Lebanon の論文,
"Conditional Models on the Ranking Poset"
[link]
が何をやっているか, だいたいわかるように
なりました。万歳。
*1: これは僕もやってみましたが, パープレキシティは下がらなかったので
発表しなかった。
*2: ここで, LDAの柔軟性が一つ崩れているのに注意.
*3: データがほぼ同じドメインだと思っているので, 文書が同じ構造に従うという仮定と
同じように, この仮定はやや強すぎるきらいがある。
グラフィカルモデル等で, 数式(変数)の入った図を書く必要のある
ことがよくあると思います。
前に
DMの論文
を最初に見た時に, かなり頑張って描いているなあと思ったのですが,
ちょうど査読をしていて同じような図に出会ったので, ちょっと紹介。
もうご存知の方は飛ばして下さい。
上は確かIllustratorで描いていると聞いた気がするのですが,
こういう数式の入った図は,
Tgif2tex
を使うと綺麗に描くことができます。
Tgifを使って hoge.obj として図を描いた後, % tgif2tex hoge.obj とすると
hoge.tps (文字)と hoge.dps (図)ができるので, hoge.tps の方を
\input{hoge.tps} で取り込みます。
*1
これは要するに, 図を文字とそれ以外に分けて, 文字の部分を \put{} の中に入れて
LaTeXで処理できるようにしているだけなので, 文字の部分に $\alpha$ とか
$\mathbf{w}$とか, LaTeXで書けることなら何でも書くことができます。
ホットケーキ分割
の図もこれで書いています。
ただ Tgif なので, 3次元的な図や, アニメーションを含むような図には弱いのが
欠点かもしれません。
(TeXでスライドを作る時に結構困っている。;)
文書に関しては, LaTeXのおかげで(欠点もあるとはいえ)
かなり綺麗に出せるようになっていると思うのですが, 図に関しては
頭の中のイメージを形にするのが僕も含む普通の人にはまだまだ難しいように思う
ので, これからそこら辺がもっと自由に可能になるのではないか..とか
期待していたりします。
*1: 僕は \scalebox{0.7}{\input{figure/hoge.tps}} のようにサイズを調整していた
のですが, 今ヘルプを見たら, -m [mag] で tgif2tex 側でも拡大率を指定できる模様。