計算機上で何かちょっとしたメモを取りたいとき, Windowsで暮らしている人は
紙copi(Lite)
を使えばいいのですが, Unixでは使えません。
委細かまわずChangeLogメモに全部書いてしまうという手もありますが,
検索する必要があるので, 技術的なメモはそれだけまとまっていると便利だと
感じることがあります。
ATRに移ってから, 技術メモは適当なファイルに書き足していたのですが,
そろそろ限界を感じてきたので, 環境が新しくなったのを機会に, 昔使っていた
postit.el に戻してみました。
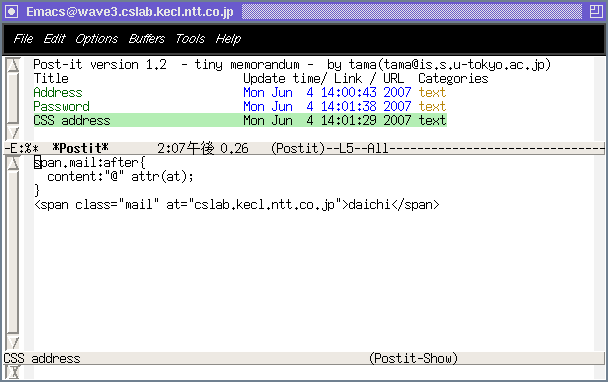
Postit.el(上の画像。クリックで拡大) は昔に玉越君が書いて,
NAISTにいた時は僕もずっと使っていたものですが,
Emacsのバージョンが上がったので使えないかと思い込んでいたら
そのまま変更なしに動くことを発見。めちゃめちゃメモが使いやすくなりました。
m でメモを書いたり, ファイルやURLにリンクを張ったり, それらを検索したりする
のがEmacsから簡単にできます。
上のEmacsは通常のFedora Coreのもので, バージョンは21.4です。
Postit.elをぐぐると,
改訂版
が置いてある
別の方のページ
がヒットしますが, こちらの新しい版では .postit のフォーマットがS式に
なっていて, やや不安(カッコが落ちると大変とか, 文字化けしたりした)
なので, 前のバージョンの1.2が個人的にはおすすめです。
前バージョンは
ここのページ
に置いてありますが(webarchive万歳), 万一ない場合は
これ
を使ってもOKです。
.emacs に,
(autoload 'postit "postit" nil t)
(define-key ctl-x-map "p" 'postit)
と書いておくだけで, C-x p で簡単にメモが使えます。
postit-1.2.tar.gz の中にマニュアルが含まれているので, 使い方はそれを見れば
okです。
岡野原君が書いている
ようにPPMをCRPとして解釈できないかという話は, MacKayのところにいる
Phil Cowans
(
Dasher
を実装したのは彼らしい)のD論
"Probabilistic Document Modeling"
にあるのを思い出したので, (細かく全て読んでいる時間はないのですが)
ざっと読んでみた。
結論から先に言うと, PPM-AはHDPの近似で, PPM-BとPPM-DはKneser-Ney(つまり
Pitman-Yor)の特別な場合です。
PPMはWitten-Bell+Katz' Back-offですが, Witten-Bellスムージングは
HDPの特別な場合です。
どういうことかというと, HDPでは各文脈で常に新しい語がBase measureから出現する
可能性がありますが, これは重複を許しているため, Base measureからこれまでと
同じ語がサンプルされる可能性があります。これが起こらない(HPYLMの言葉で言うと,
tuw=1)の場合は, HDPのスムージングはWitten-Bellと等しくなります。
さて実際には, HDPは0-gramまで再帰的に確率を混合するのに対し,
PPMは見つかった最長の文脈を使うという点に違いがあります。
このためにPPMではExclusionという方法を使いますが, これはKatz' Back-off
と同じです。
ゆえに, これがHDPの再帰的な混合とどう違うのかというのが問題となるわけですが,
上のCowansのD論ではこれを実際に調べて, PPM(つまり, Witten-Bell+Katz' Back-off)
はHDPのかなり良い近似になっている, という結論に達しています。
具体的に言うと, 近似の具合はHDPのconcentrationパラメータαの値によりますが,
これが典型的な値(5〜10くらい)の間はほとんど違いがなく, それよりαが大きくなると
微妙にHDPの方が良くなる(さらにαが大きくなると, Exclusionを行わない方が近似が
良くなる)という結果になるようです。
一方, PPM-BとPPM-Dはそれぞれ, Kneser-Neyでディスカウント係数dが
1.0と0.5の特別な場合です。
Pitman-Yorの言葉で言うと, θが0で, dが1.0または0.5, かつ上で書いたように,
tuwが常に1であるような(これがK-Nが近似である理由), Pitman-Yor過程の特別な場合です。
岡野原君のエントリを最初に読んだ時に, これはKneser-Ney(=Pitman-Yor)だろうと
パッと思ったのですが, θも0になっている特別な場合なので, すぐにわからなかった。;
というわけでまとめると,
- PPM-A, PPM-C = Witten-Bell + Katz' Back-off 〜 HDP
- PPM-B, PPM-D = Kneser-Ney の特別な場合 〜 階層Pitman-Yorの特別な場合
ということで, 圧縮で経験的に高性能だった手法は自然言語処理/音声言語処理の
手法と同じだった, という結論になるようです。