y 〜 Bernoulli(σ(x)) = Bernoulli (1 / (1 + exp(-x)))になっているようなモデル。回帰モデルでは x がさらに wTxと回帰になっている場合を考えますが, 議論は基本的に同じです。
x 〜 N(0,σ2)
これは多項分布の場合はいわゆる対数線形モデルで, 自然言語処理では通常 gradientを計算してL-BFGSやSGDなどの最適化で解くことが多いと思います。 ただし, 最適化の前提となる共変量xが既知ではなく, 学習途中に決まる 潜在変数だったりすると, 最適化してしまうと最初に変な局所解にトラップされて しまい, 学習がうまく動かなくなります。
このため, 例えばBleiの Dynamic Topic Modelではロジスティック正規分布を
下から変分近似して解く方法が示されています。
僕もなぜか長い間, ロジスティック正規分布はこうやって近似するしか
ベイズ推定する方法はないのかと思っていたのですが, 最近研究で必要があって
調べたところ, 補助変数を使ってまったく問題なく正しくベイズ推定できることを
知りました。以下, すでに知っているという方は飛ばして下さい。
論文は Groenewald&Mokgatlhe (2005)
"Bayesian computation for logistic regression"です。
実は Paul Damien, Jon Wakefield, Stephen Walker(1999),
"Gibbs sampling for Bayesian non-conjugate and hierarchical models by
using auxiliary variables", JRSS B. の方が著者は有名で, 本質的に同じ内容が
一部書かれていますが,
この論文は最初見たときさっぱり分からず, 最初の論文の方が回帰の場合,
多項分布の場合や順序変量の場合など一般的な場合を丁寧に扱っていてわかりやすい
ので, そちらの方がお薦めです。
さて, 基本的な戦略はプロビット回帰の場合の有名な Albert&Chib (1993)と同じで,
「観測値を得るために本来あるはずの変数」を潜在変数にして, 補助変数として
サンプリングすること。
以下は x を直接推定する場合を考えていますが, xが
wTxのように回帰になっている場合も同じで, 論文にはむしろこちらが書かれています。
具体的には, ロジスティック回帰で p=σ(x)=1/(1+exp(-x)) のとき, 観測値 y が1だということは, [0,1] の一様乱数 u があって u < p だったということなので,
p(y|x) = (σ(x))y (1-σ(x))1-yの補助変数 u との同時確率は,
p(y,u|x)になります。
= I[u≦σ(x)]y I[u>σ(x)]1-y …(1)
= I[x≧log (u/(1-u))]y I[x<log (u/(1-u))]1-y …(2)
よって, (1)式から u に依存する項を取り出せば, p(u|y,x)∝p(u)p(y,u|x) なので
- y = 1 のとき p(u|y,x)∝p(u) I[u≦σ(x)] = Unif(0,σ(x))
- y = 0 のとき p(u|y,x)∝p(u) I[u>σ(x)] = Unif(σ(x),1)
- y = 1のとき p(x|y,u) ∝ p(x) I[x≧log (u/(1-u))]
- y = 0のとき p(x|y,u) ∝ p(x) I[x< log (u/(1-u))]
一般には y は1つではなく, Y = [1 1 0 1] のように複数の観測値があるのが普通 なので, この場合は上式の掛け算を考えると, truncated Gaussian は
p(x|Y,U) ∝ p(x)I(a<x<b),になります。なお, 論文ではこれが掛け算(Π)ではなく, 突然Σで書かれていて, 恐らく間違っているので注意が必要です。Σにしてしまうと, 上式のmaxやminが 導けないはずです。
a = maxi log ui/(1-ui) for yi=1
b = mini log ui/(1-ui) for yi=0
というわけで, MATLABでプログラムを書いて確かめてみました。
スクリプトはこちらです。
blogis.m
なお, truncated Gaussianからの生成は, 単純に正規分布から生成してから,
範囲に入るまでrejectすればokです。原理的には, 幅が小さいときは効率が悪くなる
ので, Chopin (2012)ではテーブルを使って高速化する方法が示されているようです。
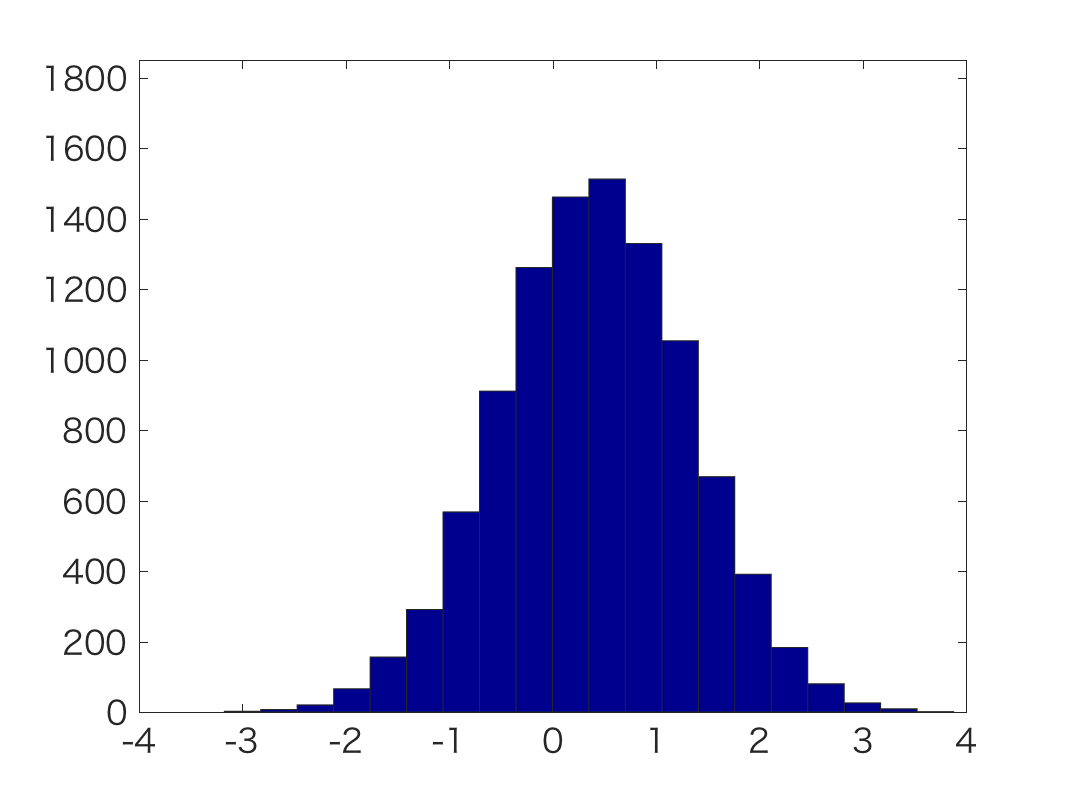 | 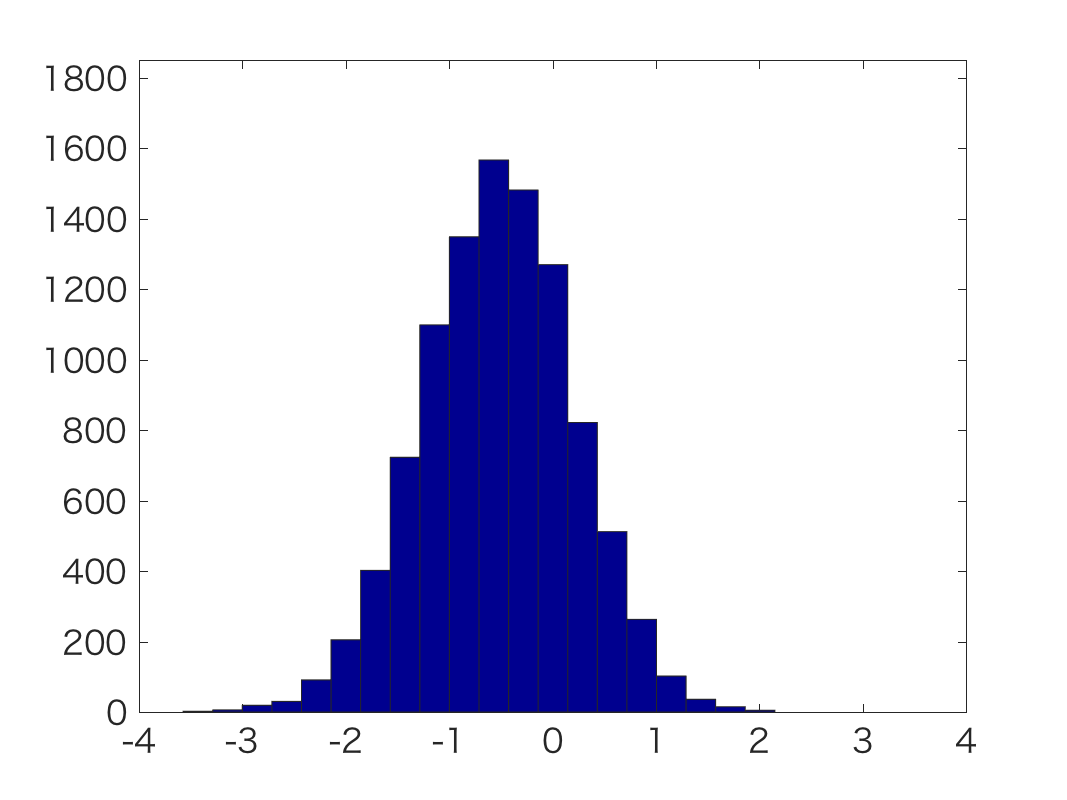 | 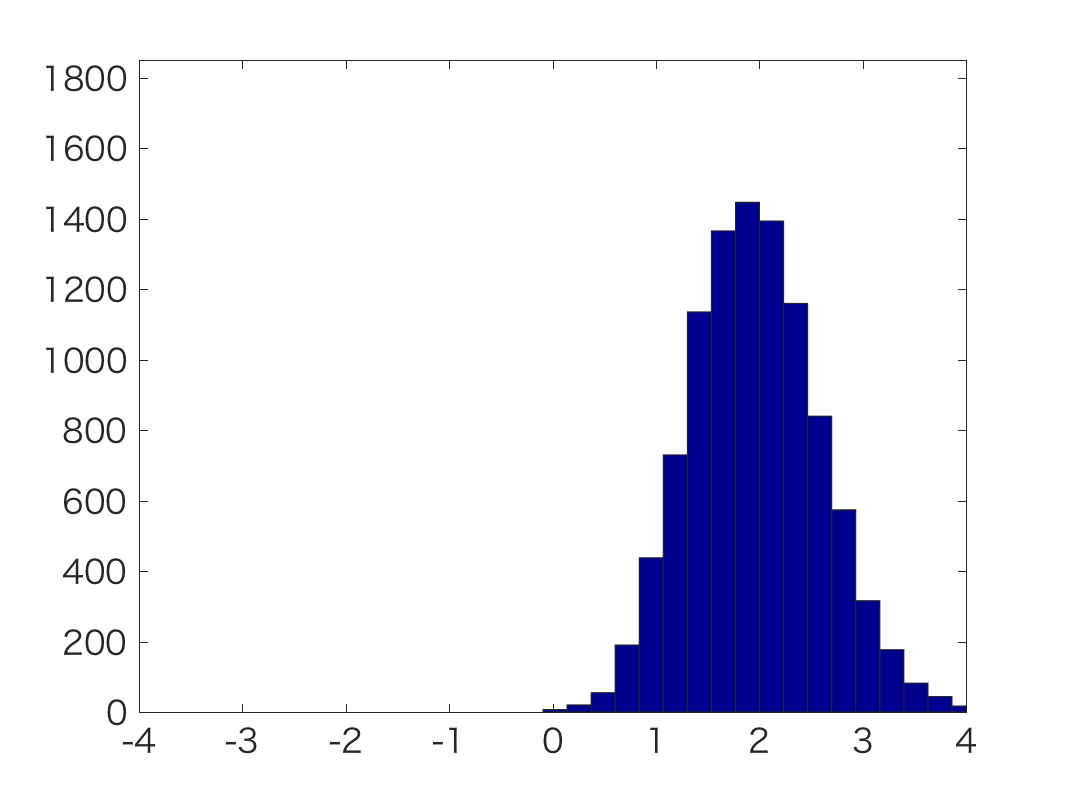 |
| y=[1] | y=[0 0 1 0] | y=[1 1 1 1 1 1 1 1 1 1 1 1 1] |
下のyが観測値です。
これからわかるように, 綺麗にガウス分布状となる事後分布が推定できています。
y=111111111111のような分布は横が歪んでいるので, 単純な正規分布ではないことが
わかります。
上で書いたように, 回帰係数 w を推定する場合も方法は同じなので(論文参照),
これでロジスティック回帰も問題なくベイズ推定することができるので安心しました。