ЄГЄЮЪ§ЫЁЄђГШФЅЄЗЄЦ, Researcher2VecЄЫЄтЄЂЄыЄшЄІЄЫ, ГЦИІЕцМдЄЮЁжИІЕцМдЅйЅЏЅШЅыЁзЄђЗзЛЛЄЙЄыЄГЄШЄЧ, ЅЁМЅяЁМЅЩЄЋЄщИІЕцМдЄђИЁКїЄЧЄЄы"ACL2Vec-authors"ЄђЄЕЄщЄЫИјГЋЄЗЄоЄЗЄПЁЃ ЁжScoreЁзЄШЄЯ, ИЁКїЅЁМЅяЁМЅЩЄЋЄщЗзЛЛЄЗЄПВОСлХЊЄЪЪИНёЅйЅЏЅШЅыЄШИІЕцМдЅйЅЏЅШЅыЄЮЅГЅЕЅЄЅѓЕїЮЅЄЮЄГЄШЄЧЄЙЁЃ(ЅЏЅъЅУЅЏЄЧГШТч)
 |  |
ЄГЄьЄЯИЕЁЙЄЯЛфЄЌTACLЄЮEditorЄШЄЗЄЦККЦЩМдЄђИЋЩеЄБЄыЄЮЄЫ, ВПЄЋМЋЦАВНЄЌЩЌЭзЄРЄШДЖЄИЄЦГЋШЏЄЗЄПЄтЄЮЄЪЄЮЄЧ, ЅЁМЅяЁМЅЩЄђЦўЄьЄыЄРЄБЄЧЄЪЄЏ, ЯРЪИЄЮPDFЄђЛиФъЄЙЄыЄШ, ЦтЩєЄЧЄНЄьЄђЅЂЅУЅзЅэЁМЅЩЄЗЄЦЅЦЅЅЙЅШЄЫФОЄЗЄЦВђРЯЄЗ, ЄНЄЮХ§ЗзЮЬЄЋЄщКЧЄтЖсЄЄИІЕцМдЄђЩНМЈЄЙЄыЅЗЅЙЅЦЅрЄтДоЄсЄоЄЗЄПЁЃ
ОхЕЄЮЅЄЅѓЅПЁМЅеЅЇЁМЅЙЄЯАьИЋДЪУБЄЫИЋЄЈЄоЄЙЄЌ,
HTMLЄЮ<input type="file">ЄђЄНЄЮЄоЄоЛШЄІЄШ, submitИхЄЫЛиФъЄЗЄПЅеЅЁЅЄЅыЬОЄЌОУЄЈЄЦЄЗЄоЄЄЄоЄЙЁЃ
ЄГЄЮЄПЄс, МЋСАЄЧЪЬЄЫРжЄЄЅмЅПЅѓЄЮ<input type="button">ЄђЭбАеЄЗ, ЄНЄьЄђЅЏЅъЅУЅЏЄЙЄыЄШCSSЄЧШѓЩНМЈЄЫЄЗЄПИЋЄЈЄЪЄЄ
<input type="file"> ЄЌЕЏЦАЄЕЄь, ЄНЄЮОѕТжЄЌЪбЙЙЄЕЄьЄыЄШЅеЅЁЅЄЅыЪИЛњЮѓЄЌНёЄДЙЄяЄыЄшЄІЄЫЄЙЄы, ЄШЄЄЄІЄшЄІЄЪJavascriptЄШCSSЄђНёЄЏЩЌЭзЄЌЄЂЄъ, ЧЏЫіЄЫЅГЁМЅЧЅЃЅѓЅАЄЗЄоЄЗЄПЄЌ, РЕЄЗЄЏЦАЄЏЄоЄЧЄЋЄЪЄъТчЪбЄЧЄЗЄПЁЃ(ЫмПІЄЮwebЅЧЅЖЅЄЅЪЁМЄЮЪ§ЄЧЄЂЄьЄа, ЄГЄЮЄЏЄщЄЄЄЯЭОЭЕЄЪЄЮЄРЄШЛзЄЄЄоЄЙЄЌ..ЁЃ)
ЦтЩєЄЧЄЯPythonЄЮPDFminerЄЧPDFЄђЅЦЅЅЙЅШВНЄЗЄЦВђРЯЄЗЄЦЄЄЄоЄЙЄЌ, PDFЄЫЄшЄУЄЦЄЯМКЧдЄЙЄыЄГЄШЄЌЄЂЄыЄПЄс, ЄНЄЮОьЙчЄЯЄНЄьЄђМЋЦАХЊЄЫИЁНаЄЗЄЦPyPDFЄЮЪ§ЄЧНшЭ§ЄЙЄы, ЄШЄЄЄІЄшЄІЄЪЛХСШЄпЄЫЄЪЄУЄЦЄЄЄоЄЙЁЃPDFЄђВђРЯЄЗЄПЗыВЬ, ВМЕЄЮЪ§ЫЁЄЧЗзЛЛЄЕЄьЄыЄНЄЮЯРЪИЄЮХ§ЗзХЊЄЪЅЁМЅяЁМЅЩЄЌЩНМЈЄЕЄьЄыЄПЄс, ЄНЄЮАеЬЃЄЧЄтЗыЙНЬЬЧђЄЄЄШЛзЄЄЄоЄЙ(БІЄЮВшСќ)ЁЃ
ЄЕЄщЄЫ, УБЄЫИІЕцМдЄЮЬОСАЄЌЩНМЈЄЕЄьЄыЄРЄБЄЧЄЯЄЩЄѓЄЪПЭЄЋЄЌЪЌЄЋЄщЄЪЄЄЄПЄс, ЭНЄсИІЕцМдЄђЩНЄЙЅЁМЅяЁМЅЩЄђХ§ЗзХЊЄЫЗзЛЛЄЗЄЦЄЊЄ, ОхЕЄЮВшСќЄЮЄшЄІЄЫЄНЄьЄђЩНМЈЄЙЄыЄшЄІЄЫЄЗЄоЄЗЄПЁЃ
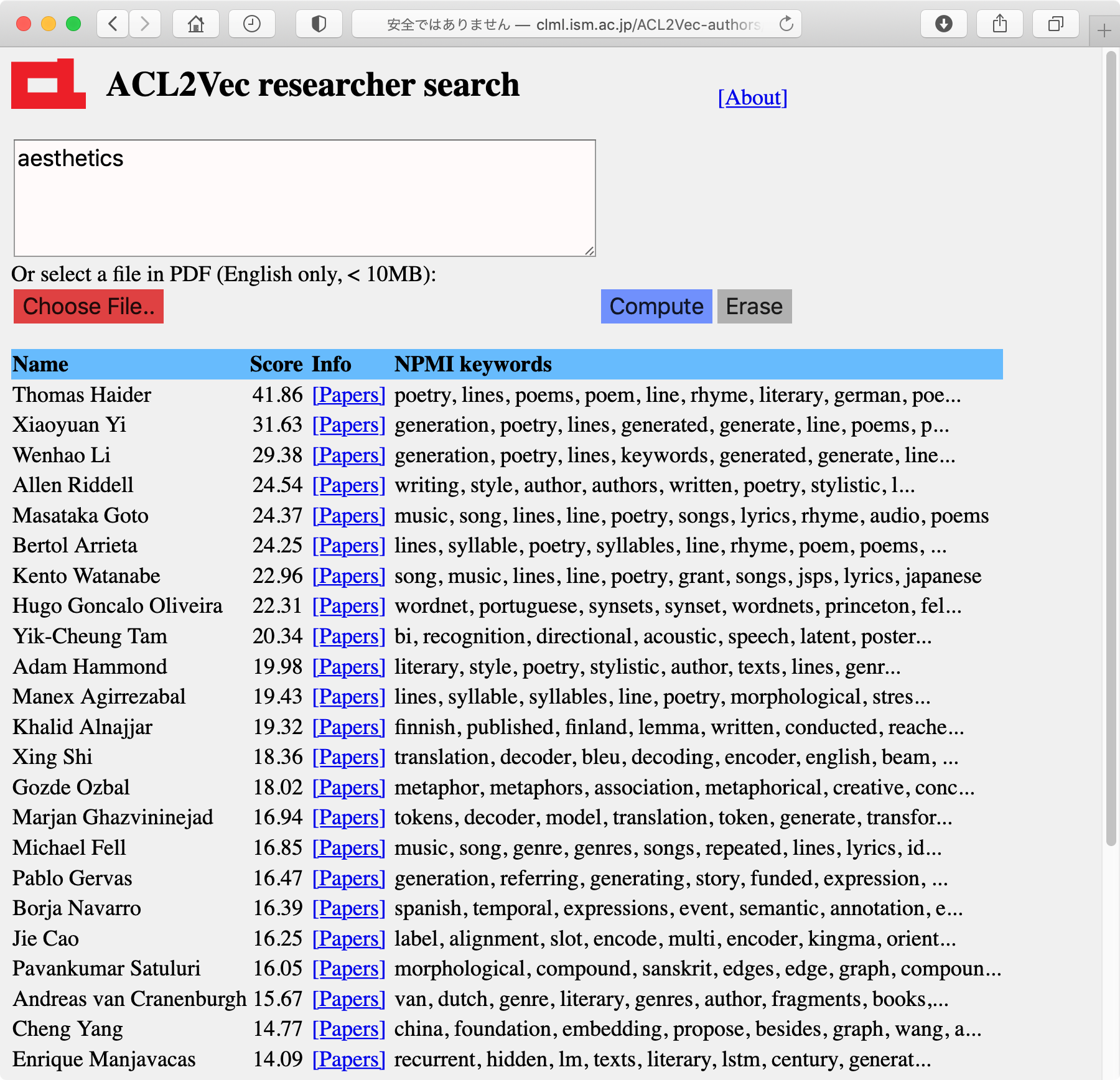
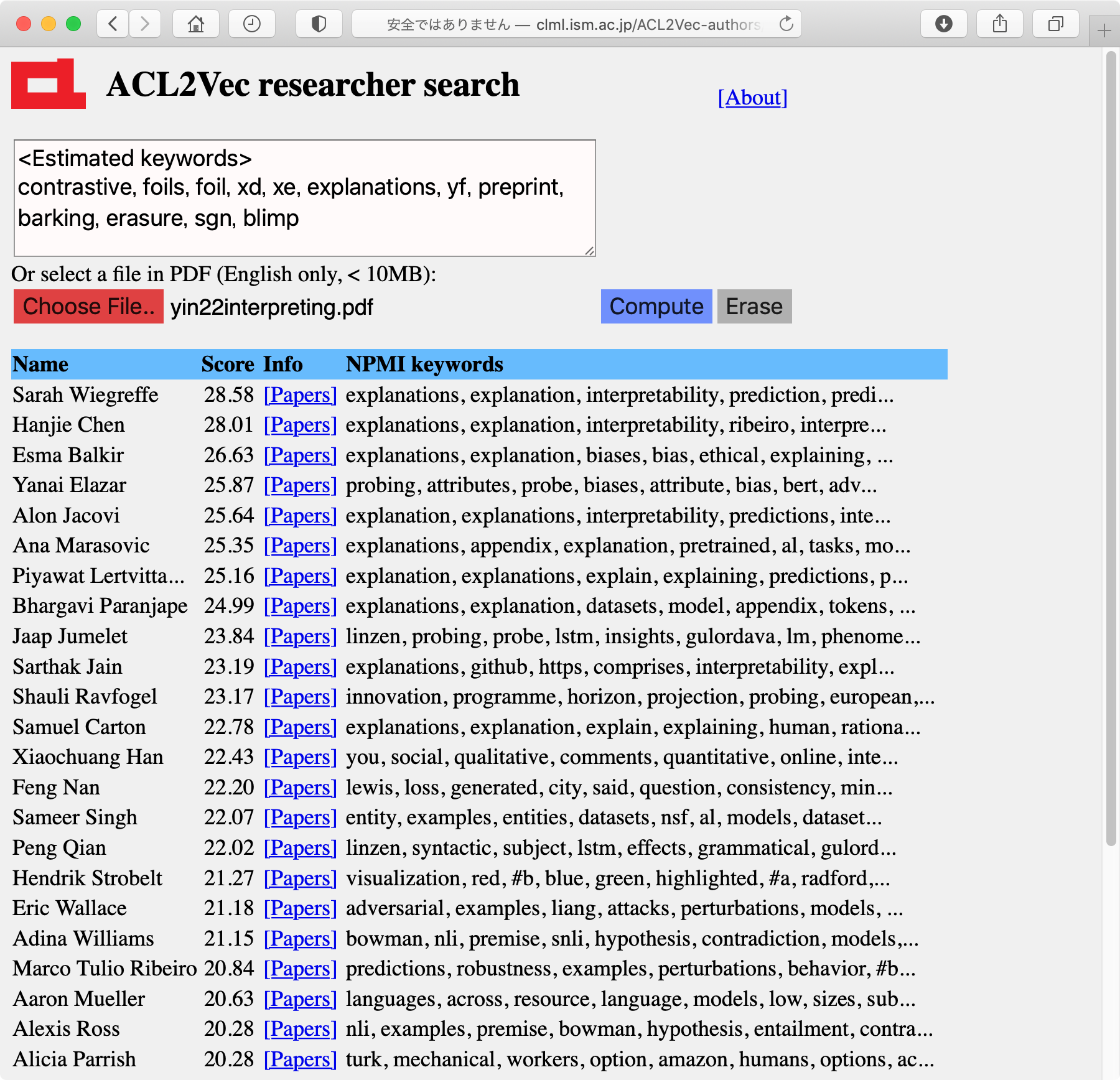
ЄГЄьЄЯ, ГЦИІЕцМдЅйЅЏЅШЅыЄЋЄщЭНСлЄЕЄьЄыУБИьГЮЮЈЄЮNPMI (Normalized PMI)ЄЮОхАЬЄђЩНМЈЄЗЄПЄтЄЮЄЧЄЙЁЃ
ЖёТЮХЊЄЫЄЯ, ИІЕцМд a ЄЌУБИь w ЄђНаЮЯЄЙЄыГЮЮЈ p(w|a) ЄЯЅтЅЧЅыЄЋЄщЕсЄсЄыЄГЄШЄЌЄЧЄЄоЄЙЄЌ, ЄГЄьЄђwЄЮЪПЖбХЊЄЪГЮЮЈЄШШцГгЄЗЄЦТаПєЄђЄШЄУЄП log p(w|a)/p(w) ЄЯИІЕцМдaЄШУБИьwЄЮМЋИЪСъИпО№ЪѓЮЬ(PMI)ЄђЩНЄЗЄЦЄЄЄоЄЙЁЃЄПЄРЄЗЄГЄьЄЯ, wЄЮГЮЮЈp(w)ЄЌОЎЄЕЄЄЄШВсЩвЄЫШПБўЄЙЄыЄПЄс, PMIЄЮКЧТчУЭЄЧЄЂЄы -log p(w,a) ЄШЄЮШцЄђЄШЄУЄПNPMIЄђЭбЄЄЄыЄЮЄЌХЌЄЗЄЦЄЄЄоЄЙЁЃ
КЃЄЮОьЙч, wЄШaЄЌДАСДЄЫСъДиЄЗЄЦЄЄЄьЄа, p(w,a)=p(w)=p(a)ЄЪЄЮЄЧ, NPMIЄЯ
NPMI(w,a) = - (log p(w|a)/p(w)) / (log p(w))ЄЧЕсЄсЄыЄГЄШЄЌЄЧЄЄоЄЙЁЃ
МТКнЄЫЗзЛЛЄЗЄЦЄпЄыЄШ, ЄГЄьЄЯИІЕцМдЄЮЦУФЇЄђЄЋЄЪЄъРЕГЮЄЫЩНЄЗЄЦЄЊЄъ, ШѓОяЄЫЬЬЧђЄЄО№ЪѓЄЫЄЪЄъЄоЄЗЄПЁЃACL anthologyЄЫ5ЫмАЪОхЯРЪИЄЌЄЂЄыИІЕцМд8963ПЭЄЮХ§ЗзХЊЄЪNPMIЅЁМЅяЁМЅЩЄђЗзЛЛЄЗЄПЄтЄЮЄЌ
ЄГЄСЄщ
ЄЧЄЙЁЃ(ЯРЪИПєЄЮТПЄЄНч)
ЄГЄьЄЯ, МЋСГИРИьНшЭ§ЄЮИІЕцМдЄЫЄШЄУЄЦЄЯ, ЄЄЄЏЄщИЋЄЦЄЄЄЦЄтЫАЄЄЪЄЄЄлЄЩЄЮО№ЪѓЄЪЕЄЄЌЄЗЄоЄЙЁЃЄПЄШЄЈЄаООЫмРшРИЄфЅАЅщЅрЄЕЄѓЄЮNPMIЅЁМЅяЁМЅЩЄЯ
Yuji Matsumoto japanese, method, dependency, word, pos, proposed, corpus, because, parsing, words Graham Neubig translation, bleu, nmt, languages, decoder, language, source, training, model, resourceЄШЄЪЄУЄЦЄЊЄъ, ГЮЄЋЄЫЄНЄІЄЄЄІЕЄЄЌЄЗЄоЄЙЁЃ ЭЬОНъЄЧЄЯЮуЄЈЄа
Dan Klein parsing, manning, petrov, parse, over, likelihood, collins, substantially, penn, model Kathleen McKeown summarization, summary, summaries, generation, views, sentences, content, sentence, document, produce Mark Steedman ccg, categorial, combinatory, parser, category, parsing, derivations, np, categories, derivationЄЧ, ЄГЄьЄтШѓОяЄЫТХХіЄЪЗыВЬЄЫЛзЄЈЄоЄЙЁЃ ЄЪЄЊ, ЛфМЋПШЄЮЅЁМЅяЁМЅЩЄЯ
Daichi Mochihashi bayesian, gram, probability, japanese, sampling, segmentation, dirichlet, distribution, gibbs, wЄЧ, ACLЗЯЄЮЯРЪИЄЫИТЄУЄЦЄпЄьЄаГЮЄЋЄЫЄНЄІЄРЄэЄІЄЪЄШЛзЄЄЄоЄЙЁЃ МТКнЄЫЄЯЛфЄЯЅэЅмЅЦЅЃЅЏЅЙЄЪЄЩТОЄЮЪЌЬюЄЮЯРЪИЄтНаЄЗЄЦЄЄЄыЄЮЄЧ, ЄтЄЗСДТЮЄЮЅЧЁМЅПЅЛЅУЅШЄЧЗзЛЛЄЧЄЄПЄШЄЙЄыЄШ, ЄтЄІОЏЄЗХ§ЗзХЊЄЪЅЁМЅяЁМЅЩЄЯЪбЄяЄыЄЮЄЧЄЯЄЪЄЄЄЋЄШЛзЄЄЄоЄЙЁЃ
ЄЪЄЊ, ACL2Vec-authorsЄШЦБЭЭЄЪИІЕцМдПфСІЅЗЅЙЅЦЅрЄЯ, ЛфЄЌЪЌРЯИІЕцАїЄђЬГЄсЄыЦќЫмГиНбПЖЖНВёЄЮГиНбО№ЪѓЪЌРЯЅЛЅѓЅПЁМЄЧЄЙЄЧЄЫВдЦЏЄЗЄЦЄЄЄоЄЙЄЌ, ЅЁМЅяЁМЅЩЄфЯРЪИPDFЄЫД№ЄХЄЄЄЦЦАХЊЄЫПфСІЄђЙдЄІЅЗЅЙЅЦЅрЄЮМТСѕЄЯ, КЃВѓЄЌНщЄсЄЦЄШЄЪЄъЄоЄЙЁЃ