lwlm, The Latent Words Language Model.
 Daichi Mochihashi
Daichi Mochihashi
NTT Communication Science Laboratories
$Id: lwlm.html,v 1.1 2010/03/19 10:15:06 daichi Exp $
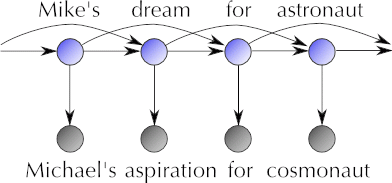
lwlm is an exact, full Bayesian implementation of the Latent Words Language
Model (Deschacht and Moens, 2009). It automatically learns synonymous words
to infer context-dependent "latent word" for each word appearance,
in a completely unsupervised fashion.
Technically, LWLM is a higher-order hidden Markov model over words where the
latent dimension equals the dimension of lexicon, or a "class-based" n-gram
model where the number of classes equals the number of word types.
This high dimensionality and higher-order model structure preclude ordinary
EM algorithms, and necessitates a Gibbs sampler for learning.
In this toolkit, I further extended it as wholly Bayesian, and newly introduced
"sliced" Gibbs sampler to cope with possible difficulty of the high
dimensionality of latent words that must be considered.
Additionally, lwlm includes a complete implementation of the hierarchical
Pitman-Yor language model (HPYLM) (Teh, 2006) as its submodel.
Requirements
- GNU C++ compiler. (developed with g++ 4.1.1)
- Note the implementation uses <ext/hash_map>, which seems
deleted in the latest g++.
- Google
sparsehash must be installed beforehand. (built with sparsehash-1.6)
Downloads
- Source: lwlm-0.1.tar.gz
- Precomputed Model:
- New York Times model:
- model-nyt.n3.tar.gz
(recommended) [4.9MB]
- This is a model learned from random 100K sentences from the
New York Times, 2006 January (about 2.1 million words).
Penn tokenization.
For details, see the enclosed README.
- Japanese "Mainichi" model:
- model-mai2007.n3.tar.gz
(recommended) [4.7MB]
- This is a model built from the 2007 texts of the standard
Japanese newspaper of Mainichi Newspaper, which contains
2.4 million words, 100K sentences. For details, see the
enclosed README.
- FSNLP "austen" model:
- model-austen.tar.gz
[3.2MB]
- This is a model built from the text of Jane Austen's novels
available from
FSNLP (Foundations of Statistical Natural Language
Processing, MIT Press) site for
language modeling chapter.
This includes both the original text and learned model
after 400 iterations of the Gibbs sampler.
Note this model was built on a very small text.
- Japanese "Kyoto" model:
- model-kyoto.tar.gz
[2.2MB]
- This is a model built from standard Japanese corpus of the
"Kyoto corpus", which contains 1 million words,
38400 sentences.
For copyright issues, only the learned model is included
in this file (original text and learned latent words are
excluded). Note this model is still small, but suffices to
demonstrate the LWLM ability for natural language processing.
Install
- Install
Google-sparsehash if necessary.
- Take a glance at Makefile, and edit it accordingly.
- Type "make all". This builds both "lwlm" (the learner) and "lwlm-decoder"
(the decoder).
- If any problem occurs, please inform it to the author.
Getting started
Prepare an appropriate sized text or simply use
this sample data,
and invoke lwlm as (this may take a few minutes):
% ./lwlm -n 3 -N 10 persuation.txt model.austen
latent ngram order = 3, alpha = 0.01
reading persuation.txt.. done.
vocabulary = 5756
parsing 1005/ 1005 ..done.
[10] : sampling 84149/ 84148.. ETA: 0:00:00 (6678 words/sec) PPL = 88.1006
done.
saving model.. done.
Or, just download the precomputed model from above and unpack it:
% tar xvfz model-austen.tar.gz
To decode latent words in a text, invoke lwlm-decode as (in zsh):
% ./lwlm-decode -K 5 -o out =(tail -10 persuation.txt) model.austen
This yields a file "out" which contains decoded latent word distributions.
For complete command-line options, try "lwlm -h" and "lwlm-decode -h" or
see the texts below.
Data format and Model files
lwlm works on any vanilla text files.
Each line in the text represents a sentence, which consists of words
separated with (possibly multiple) white spaces.
Empty lines are ignored.
Each model directory has a following file structure:
+ model --+-- lexicon Words beginning from internal id = 0.
+-- latent Sampled latent words corresponding to the training text.
+-- table Learned table of hidden -> observed translations.
+-- param Model parameters (order and alpha)
+-- log Log file during computation, esp. PPL (see below)
+-- lm HPYLM
+-- nodes Nodes and CRP restaurants
+-- tree Dependencies between nodes
+-- param HPYLM parameters (order, d, theta, lexicon)
Command line syntax
LWLM Model learner
% ./lwlm -h
lwlm, The Latent Words Languge Model.
$Id: lwlm.html,v 1.1 2010/03/19 10:15:06 daichi Exp $
Copyright (C) 2010 Daichi Mochihashi, All rights reserved.
usage: lwlm OPTIONS train model
OPTIONS
-n n-gram order (default 3, trigram)
-a Dirichlet hyperparameter of translation table (default 0.01)
-N number of Gibbs iterations
-h help
- -n [n]
- n-gram order of latent words (default 3). Generally, Larger n requires
larger data for plausible inference.
- -a [a]
- Dirichlet pseudo count for word translation matrix. Smaller counts will
induce peaky latent word distributions, while larger counts will explore
more possibilities for them.
- -N [N]
- Number of Gibbs iterations. Generally, several hundreds of iterations
will suffice for approximate convergence.
For assessing convergence, see the section below.
-
-
LWLM Decoder
% ./lwlm-decode -h
lwlm-decoder, The Latent Words Languge Model decoder.
$Id: lwlm.html,v 1.1 2010/03/19 10:15:06 daichi Exp $
Copyright (C) 2010 Daichi Mochihashi, All rights reserved.
usage: lwlm-decode OPTIONS test model
OPTIONS:
-B [b] burn-in iterations (default 100)
-N [n] number of iterations to collect samples (default 100)
-I [i] interval to collect posterior samples (default 1)
-K [K] number of possible candidates (default 5)
-e [eps] threshold for candidate probability (default 0)
-f [fmt] printf format of candidates (default "%s (%.03f) ")
-o [file] filename for output
-h this help
lwlm-decode finds latent words for the input text by running Gibbs iterations
to collect posterior samples.
Possible parameters are shown above: if "-o" option is not specified, decoded
results are printed into stdout.
Note: in order to change the output format, e.g. to create a data file
for another processing task, use "-f format" options.
This format takes two arguments,
a latent word (char *) and its probability (double), thus '-f "%s:%.04f "'
yields an output like "foo bar:0.6704 qux:0.2000 quux:0.1250".
Convergence
To assess the convergence, "log" file created in the model directory records
training data perplexity (equivalent to the negative data likelihood)
for each Gibbs iteration.
Generally, perplexity will increase and saturate after several hundreds
of iterations.
This is correct, because LWLM is essentially a model that avoids overfitting
to the training data.
Technical details
Sampling latent word for each observation is the core of the inference in the
Latent Words Language Model.
However, in principle this will incur computing probabilities over all words
in the lexicon, which are usually tens of thousands of candidates.
In order to cope with this difficulty, lwlm leverages slice sampling
(Neal 2003) for thresholding these candidates probabilistically.
However, naive thresholding would still incur computing probabilities over
all words, thus lwlm maintains a special data structure (record *)
for each n-gram node that enables to prune the candidates efficiently.
References
- "Using the Latent Words Language Model for Semi-Supervised Semantic Role
Labeling". Koen Deschacht and Marie-Francine Moens. EMNLP 2009.
[PDF]
- "The Latent Words Language Model". Koen Deschacht and Marie-Francine
Moens. In Proceedings of the 18th Annual Belgian-Dutch Conference on
Machine Learning (Benelearn 09), 2009.
[PDF]
- "Slice sampling". Radford M. Neal.
Annals of Statistics, 31(3), pp.705-767, 2003.
- "A Bayesian Interpretation of Interpolated Kneser-Ney". Yee Whye Teh.
Technical Report TRA2/06, School of Computing, NUS, 2006.
Acknowledgement
Thanks for Daisuke Okanohara for advice about efficient data structures.
daichi<at>cslab.kecl.ntt.co.jp
Last modified: Thu Mar 25 15:44:58 2010