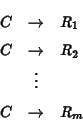

Next: 7.6 Best-First Parsing
Up: Chapter7Ambiguity Resoltion: Statistical Methods
Previous: �$B$O$8$a$K�(B
- Category C�$B$KBP$7�(B,�$B$I$N�(B rule �$B$,$I$l$@$1E,MQ$5$l$?$+$N3NN(�(B
�$B$N$H$-�(B rule Rj �$B$,;HMQ$5$l$k3NN(�(B
PROB(Rj|C) �$B$O�(B
Figure 7.17
- Viterbi algorithm �$B$r3HD%$9$l$P3NN($O4JC1$K5a$^$k�(B
- �$BLdBjE@�(B
- �$B3F�(B rule �$B$N@8@.3NN($rFHN)$H$7$F$$$k�(B
- Rj �$B$N9=@.AG$,�(B, �$B$=$N>e$G2?$NMWAG$K$J$k$N$+9MN8$5$l$J$$�(B
- NP
 ART N �$B$G�(B, NP �$B$,�(B subject �$B$K$J$k$+�(B,
verb of object �$B$K$J$k$+�(B object of a preposition�$B$K$J$k$+�(B?
ART N �$B$G�(B, NP �$B$,�(B subject �$B$K$J$k$+�(B,
verb of object �$B$K$J$k$+�(B object of a preposition�$B$K$J$k$+�(B?
- subject �$BCf$N�(B NP �$B$O�(B, NP �$B$h$j�(B pronouns �$B$K$J$j$d$9$$�(B
- inside probability
- category C �$B$,C18lNs�(B
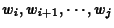 �$B$KE83+$5$l$k3NN(�(B
�$B$KE83+$5$l$k3NN(�(B
- Figure 7.18,7.19
�$B$r5a$a$F$_$h$&�(B (buttom up)
PROB(flower|N),PROB(a|ART),PROB(a|N)
Figure 7.6
�$B$7$+$7�(B sentence �$B$,$"$kFCDj$NC18lNs$KE83+$5$l$k3NN($r5a$a$F$b0UL#�(B
�$B$,$J$$�(B, �$B$`$7$mC18lNs$,M?$($i$l$?$H$-$K$I$N$h$&$J�(B rule �$B$,E,MQ$5$l�(B
�$B$k$+$,=EMW�(B
- �$B$"$kFCDj$N�(B parse tree�$B$,E,MQ$5$l$k3NN(�(B
- �$BC18lNs�(B
�$B$KBP$7$F�(B, �$B$"$k�(B parse tree �$B$,F@$i$l�(B
�$B$k3NN($r5a$a$k�(B
�$B$H$$$&�(B rule i �$B$,E,MQ$5$l$k3NN($O�(B
�$B$H$J$k�(B
-
PROB(E) �$B$,�(B lexical category (�$BIJ;l�(B) �$B$K$J$C$?>l9g$O�(B, 7-4 �$B$G=R$Y$?�(B
Lexical Probabilites �$B$r;HMQ$9$k�(B
context-independent �$B$J3NN(�(B (Figure 7.13)�$B$G$O�(B..
�$B$G$"$j�(B V �$B$r$_$?$9>l9g9M$($i$l$k�(B,�$B$7$+$7�(B context-dependent
(Figure 7.16) �$B$D$^$j�(B,
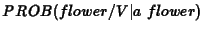 �$B$r5a$a$k$H�(B
flower/V �$B$K$J$k2DG=@-$O6K$a$FDc$$�(B (a
N, flower
V)
�$B$r5a$a$k$H�(B
flower/V �$B$K$J$k2DG=@-$O6K$a$FDc$$�(B (a
N, flower
V)
- �$B6qBNNc�(B
``a flower'' �$B$KBP$7$F�(B, context-dependent �$B$J3NN($r;H$C$F�(B
Chart Parsing �$B$r9T$C$?Nc�(B
Figure 7.20 - �$B$7$+$7$3$l$G$b�(B50% �$BDxEY$N@:EY$7$+F@$i$l$J$$�(B
�$B3F�(B rule �$B$rFHN)$J$b$N$H$7$F2>Dj$7$F$$$k$?$a�(B
(�$B6qBNNc�(B) Figure 7.21
VP �$B$,�(B (V,NP,PP) �$B$KE83+$5$l$k3NN($O05E]E*$K�(B
Figure 7.21 �$B$N:8$NLZ$N2DG=@-$,9b$$�(B,
courps �$BCf$K�(B 23 �$BNc$"$k�(B NP
NP PP �$B$O�(B
�$B$9$Y$F8m$C$F2r@O$5$l$F$7$^$&�(B
84�$B$NJ8$G�(B �$B3NN($r;H$o$J$+$C$?>l9g�(B 1/3 �$B$,@52r�(B
�$B3NN($r;H$C$?>l9g�(B 1/2 (�$B$?$@$7�(B closed test),
open test �$B$K$7$?$i$b$C$H0-$/$J$k�(B
context �$B$K0MB8$7$?3NN($r;H$C$F�(B parsing �$B$r9T$&I,MW$"$j�(B
Next: 7.6 Best-First Parsing
Up: Chapter7Ambiguity Resoltion: Statistical Methods
Previous: �$B$O$8$a$K�(B
1999-08-03