普通はクエリを増やすと, それだけ結果が絞れて精密になるはずなのだが,
>> bsshow(bsets(M,[582 191 132 143],alpha,beta),'movie.txt'); % 「アマデウス」「ピアノ・レッスン」「オズの魔法使い」「サウンド・オブ・ミュージック」で検索 loading movie.txt.. done. 191 493.445 Amadeus (1984) 132 410.556 Wizard of Oz, The (1939) 174 366.719 Raiders of the Lost Ark (1981) *98 358.637 Silence of the Lambs, The (1991) *318 340.908 Schindler's List (1993) *172 321.592 Empire Strikes Back, The (1980) *69 320.884 Forrest Gump (1994) 143 319.785 Sound of Music, The (1965) 357 316.532 One Flew Over the Cuckoo's Nest (1975) 483 313.525 Casablanca (1942) *423 309.385 E.T. the Extra-Terrestrial (1982) *64 299.934 Shawshank Redemption, The (1994) *204 292.22 Back to the Future (1985) 173 285.095 Princess Bride, The (1987) *168 280.25 Monty Python and the Holy Grail (1974) 196 277.245 Dead Poets Society (1989) *28 276.291 Apollo 13 (1995) 496 270.269 It's a Wonderful Life (1946) 427 268.64 To Kill a Mockingbird (1962) *50 263.816 Star Wars (1977)'*' を付けた結果が, 明らかに間違っているエントリ。 クエリを増やすと一般にこういうことが起こって, 大域的に人気の高い映画が (p(x)で正規化しているにもかかわらず)出てきてしまう。
これはどうしてかというと, 重みベクトルの作り方に依存している。 最初の例の重みベクトル w_0 と, 後の例の重みベクトル w をプロットしたものが 以下。
「スターウォーズ」のような映画は多くの人が評価し, 素性として多くの1を 持っているので, この重みベクトルと内積を取った場合に, スコアがかなり高く なってしまう。
w0: query = [582] w: query = [582 191 132 143]
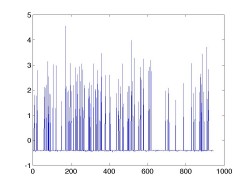
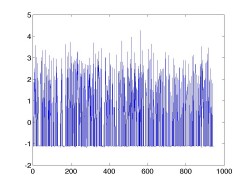
この理由は、二つ考えることができる。重みベクトル w は, 各素性の持つ(バイナリなので)ベータ分布のハイパーパラメータ α, β および, n 個の要素を持つクエリ(に対応するデータ行列の部分行列)中の素性の カウント c を使って以下のように書けるが (論文では q と書かれている)
w = log(α+c) - log(β+n-c) - logα + logβこれは, c = 0 の場合(素性はスパースなので, これがほとんど),
w = logβ - log(β+n)に等しくなる。ここで, 一つでもクエリが素性を持っていて c = 1 になると,
w = log(α+1) - logα + logβ - log(β+n-1)になる。
これは, 後半の第3項と第4項は c = 0 の場合とほとんど一緒 (1の差があるが, log を取っているのできわめて微妙にしか小さくならない) なのに対し, αは「疎行列の中で各素性に1が立つ事前確率」なので通常かなり 小さい値であるため, 前半の log(α+1) - logα = log(1 + 1/α) はかなり大きい値になって, この素性の重み が一気に大きくなる。これを表しているのが上のグラフで, クエリの数が増える ほど, 立っているスパイクの数が増えて, 1を多く持つエントリとの内積が大きく なってしまう。(第4項のせいでスパイクの底が少し下がっているが, スパイクの増え方に比べるとその影響はかなり小さい。)
この問題に対応するために, 論文の方ではデータを列に関して正規化する ことが書かれているが, これはアドホックであるうえ, p(x) の影響を2回評価する ことになるので, いい方法ではない。実際にやってみると, 行列を縦に正規化して しまうと, ビットがほとんど立っていない, 非常に頻度が低いアイテムが上位に来て しまい, 何も正規化しない方がまだよい結果を出すことがわかった。
もう一つ, この理由は十分統計量の作り方にも関連している。
Bayesian Sets では, 素性がクエリに対応するサブ行列の中で何回現れたか
という総和 c だけを使っているので, 例えばクエリに対応するサブ行列が
[1 1 1 0 0 0], [0 0 0 1 1 1] だった場合, 十分統計量はこの和として
[1 1 1 1 1 1] になってしまい, 直感的には 1 を多く持つエントリとの内積が
大きくなってしまう。これは, 素性空間上に一つの分布を仮定していることに
恐らく対応すると思うので, その平均が例え確率密度が薄くても, データを表現
していると解釈されてしまうという問題。
これは
2005/11/11
のIBISでの話と似たところがあって, 複雑な分布をきちんと表現するためには,
例えばカーネルで高次元に飛ばす, という方法もあるような気がする。
(Kernel Bayesian Sets?) これは単にそう思っただけなので, rigid な根拠が
あるわけではないけれども。
ということで, だいたい書きたいことを書いたので, NL研の話の方をやろうと
思います。