Percy Liang ΛΈ "Type-Based MCMC" (NAACL 2010)
[PDF]
Λρ≤Ω≤σΛΪΛΥ §Λ±ΛΤΤ…ΛσΛ«ΛΛΛΤ, ΛηΛΠΛδΛ·ΛέΛήΆΐ≤ρΛ«Λ≠ΛΩΓΘ
Λ≥ΛλΛœΛΙΛ¥ΛΛœά ΗΛ«ΛΙΓΘ»σΨοΛΥ¥πΝΟ≈ΣΛ œΟΛ«, ≈ΐΖΉΛΈάλΧγΞΗΞψΓΦΞ ΞκΛΥΛβΆΨΆΒΛ«
ΡΧΛκœΟΛάΛ»ΜΉΛΛΛόΛΖΛΩΛ§, NAACLΛ»ΛΛΛΠΓΘMichael JordanΛ§¬η2(¬η3Λ«Λ Λ·)ΟχΦ‘Λ ΛΈΛ«,
Ε≤ΛιΛ· Jordan ΛΈΞΤΞΛΞΙΞ»Λ§ΖκΙΫΤΰΛΟΛΤΛΛΛκΛΈΛάΛ»ΜΉΛΛΛόΛΙΓΘ
ΛηΛ·Λ≥ΛλΛάΛ±ΛΈΤβΆΤΛρ8ΞΎΓΦΞΗΛΥΫώΛΛΛΩΛ ΛΓ..Λ»ΛΛΛΠΛΈΛ§Κ«ΫιΛΈ¥ΕΝέΛ«, ΛΝΛ ΛΏΛΥ,
ΛΪΛ ΛξΞΌΞΛΞΚ≈ΣΛ ΒΡœάΛΥ¥ΖΛλΛΤΛΛΛ ΛΛΛ», …αΡΧΛΈΦΪΝ≥ΗάΗλΫηΆΐΛΈΩΆΛάΛ»ΛΫΛβΛΫΛβ≤ΩΛρ
ΗάΛΟΛΤΛΛΛκΛΈΛΪΛΒΛΟΛ―ΛξΛοΛΪΛιΛ ΛΛΛΪΛβΟΈΛλΛ ΛΛΛ»ΜΉΛΛΛόΛΖΛΩΓΘ
Ψ·ΛΖΝΑΛΥΨπΫηœά ΗΜοΛ«Ξ»ΞσΞ«ΞβΚΚΤ…ΛρΛΒΛλΛΤΑΔΝ≥Λ»ΛΖΛΩΛΈΛ«,
ΆΨΖΉΛΥΛΫΛΠΜΉΛΠΛΈΛΪΛβΛΖΛλΛόΛΜΛσΛ§..ΓΘ
*1
Τβ…τΛΈΞΌΞΛΞΚ ΌΕ·≤ώΛ«Λœ ΧΛΈœΟ ("Painless Unsupervised Learning with Features")
ΛρΨ“≤πΛΖΛΩΛΈΛ«, Λ≥Λ≥Λ«ΦΪ §Ά―ΞαΞβΛρ¥όΛαΛΤΛόΛ»ΛαΓΘ
Λ≥ΛΈœά ΗΛœΑλΗάΛ«ΗάΛΠΛ»,Γ÷Τ±ΛΗ¥ΡΕ≠ΛΈ ―ΩτΛρΛόΛ»ΛαΛΤΞΒΞσΞΉΞξΞσΞΑΛΙΛκΓΉMCMCΛρΡσΑΤΛΖΛΤΛΛΛόΛΙΓΘ
ΛΛΛοΛφΛκ Direct Gibbs (Scott 2000)Λ«Λœ, ΈψΛ®Λ–ΕΒΜ’Λ ΛΖ… ΜλΩδΡξΛ ΛιΛ–,
≥ΤΟ±ΗλΛΈΜΐΛΡ±ΘΛλΨθ¬÷(ΓΝ… Μλ)ΛρΑλΟ±ΗλΛΚΛΡΞΒΞσΞΉΞξΞσΞΑΛΖΛΤ ―Λ®ΛΤΛΛΛ≠ΛόΛΙΛ§,
Λ≥ΛλΛœ»σΨοΛΥΦΐ¬ΪΛ§ΟΌΛΛΨλΙγΛ§ΛΔΛξΛόΛΙΓΘ
¬ΨΛΥΛœ, PCFGΛ«ΛΩΛόΛΩΛόΝ¥ΛΤΛΈ ΗΛ§ S->NP ( Η->ΧΨΜλΕγ) Λ»≤ράœΛΒΛλΛΤΛΖΛόΛΟΛΩΨλΙγ,
EMΛάΛ»άδ¬–ΛΥ S->NP VP ( ΗΔΣΧΨΜλΕγ ΤΑΜλΕγ) Λ»Λ ΛκΛ≥Λ»ΛœΛΔΛξΛόΛΜΛσΛ§, MCMCΛ«Λœ
≥ΈΈ®≈ΣΛΥΛ…ΛλΛΪΛΈ ΗΛΈ≤ράœΛ§ NP VP ΛΥΛ Λξ, ΛΫΛλΛΥ±ΰΛΗΛΤΛόΛΩ ΧΛΈ ΗΛ§ NP VP ΛΥ
Λ Λξ..Λ§ΖΪΛξ ÷ΛΒΛλΛΤ, ≤ρΦαΛ§ΑζΛΟΛ·Λξ ÷ΛκΛ≥Λ»Λ§ΛΔΛξΛ®ΛόΛΙ(Λ≥ΛλΛ§MCMCΛΈΛΛΛΛΫξ)ΓΘ
ΛΩΛάΛΖ, Λ≥ΛλΛΥΛœ»σΨοΛΥΡΙΛΛΖΉΜΜΜΰ¥÷Λ§…§ΆΉΛ«, Ξ«ΓΦΞΩΛ§¬γΛ≠Λ·Λ ΛλΛ–Λ ΛκΛέΛ…,
Ν¥¬ΈΛΈ≤ρΦαΛ§¬γΛ≠Λ· ―ΛοΛκΛηΛΠΛ ―≤ΫΛœΒ·Λ≠ΛΥΛ·Λ·Λ ΛξΛόΛΙΓΘ
ΛΖΛΪΛΖΛηΛ·ΗΪΛκΛ», Ξ«ΓΦΞΩΛΈΟφΛ«ΛœΤ±ΛΗΛηΛΠΛ Γ÷…τ §ΓΉΛ§¬τΜ≥ΛΔΛξ, ΛΫΛλΛιΛρΛόΛ»ΛαΛΤ
ΤΑΛΪΛΜΛ–, ΗζΈ®≈ΣΛΥΞΒΞσΞΉΞξΞσΞΑΛ«Λ≠Λκ≤Ρ«Ϋά≠Λ§ΛΔΛξΛόΛΙΓΘ
*2
ΈψΛ»ΛΖΛΤHMMΛ«±ΘΛλΨθ¬÷Λ§0Λ»1ΛΈΤσΨθ¬÷ΛάΛΟΛΩΨλΙγ,
0ΔΣ[1]ΔΣ1, 0ΔΣ[1]ΔΣ1, 0ΔΣ[1]ΔΣ1, ...
Δ≠ Δ≠ Δ≠
flower flower flower
ΛΈΛηΛΠΛΥ, []Λ«ΑœΛόΛλΛΩΞΒΞσΞΉΞκΛΙΛΌΛ≠±ΘΛλΨθ¬÷ΛΥΛΡΛΛΛΤ, Ξ«ΓΦΞΩΛΈΟφΛ«Τ±ΛΗΛηΛΠΛ
…τ §Λ§¬τΜ≥ΛΔΛκ≤Ρ«Ϋά≠Λ§ΛΔΛξΛόΛΙΓΘΛ≥ΛΈΨλΙγ, Ψθ¬÷[1]Λ§1Λ«ΛΔΛκΛΪ0ΛΥ ―ΛοΛκΛΪΛΈ
≥ΈΈ®ΛœΛ…ΛΈ…τ §Λ«ΛβΤ±ΛΗΛ ΛΈΛ«,
- ΛόΛΚ, nΗΡΛΈΤ±ΛΗ…τ §ΛΈΛΠΛΝ, ≤ΩΗΡΛ§ ―ΛοΛκΛΪ(mΛ»ΛΙΛκ)ΛρΞΒΞσΞΉΞκΛΙΛκ
- nΗΡΛΈΛΠΛΝ, ΛΝΛγΛΠΛ…mΗΡΛρΞιΞσΞάΞύΛΥ ―Λ®Λκ
Λ»ΛΛΛΠΝύΚνΛρΛΙΛκ, Λ»ΛΛΛΠΛΈΛ§Ξ≠ΞβΓΘΛ≥ΛλΛœΑλΦοΛΈ Blocked Gibbs Λ«, ΛΩΛάΛΖBlockΛ§
1 ΗΛΈΛηΛΠΛΥΆΫΛαΖηΛόΛΟΛΤΛΛΛκΛΈΛ«ΛœΛ Λ·, ―ΩτΛρ ―Λ®Λκ¥ΡΕ≠Λ§Τ±ΛΗΛβΛΈ(Λ≥ΛλΛρTypeΛ»
ΗΤΛσΛ«ΛΛΛκ)ΛρΫΗΛαΛΤ Block Λ»ΛΙΛκ, Λ»ΛΛΛΠΛ≥Λ»ΓΘ
Εώ¬Έ≈ΣΛΥΛœ, nΗΡΛΈΛΠΛΝmΗΡΛ§ ―ΛοΛκ≥ΈΈ®Λœ nCmΓΠg(m) ΛΥΛ ΛξΛόΛΙΓΘ
g(m)ΛœmΗΡΛ§ ―ΛοΛΟΛΩΑλΛΡΛΈάχΚΏ ―ΩτΛΈΝ»ΛΏΙγΛοΛΜΛΈ≥ΈΈ®(≈ωΝ≥Λ≥ΛλΛ§nCmΗΡΛΔΛκ)Λ«,
œά ΗΛΈ(9)ΦΑΛ«ΛΙΛ§, Λ≥ΛλΛœ≈ωΝ≥ m ΛΥΛηΛΟΛΤΑέΛ ΛκΟΆΛ«, ΈΞΜΕ §…έΛΈΜωΝΑ §…έΛΥ
Ξ«ΞΘΞξΞ·Ξλ≤αΡχ(ΛόΛΩΛœΞ«ΞΘΞξΞ·Ξλ §…έ)Λρ≤ΨΡξΛΙΛκΛ»(3)ΦΑΛ»(4)ΦΑΛΪΛιΒαΛόΛξΛόΛΙΓΘ
Λ≥Λ≥Λ«¬Ω §, (3)ΦΑΛρΑλΫ÷ΗΪΛκΛ»(?)Λ«ΛΙΛ§, ΛηΛ·ΗΪΛκΛ», Λ≥ΛλΛœΦ¬Λœ,
Ο±ΫψΛ Polya §…έΛΈΦΑΛ«ΛΔΛκΛ≥Λ»Λ§ΛοΛΪΛξΛόΛΙΓΘ
Polya §…έ(ΨήΛΖΛ·Λœ
2005/10/28ΛΈΤϋΒ≠
Μ≤Ψ»)Λ«Λœ, ΞΪΞΠΞσΞ»ΛΈάΑΩτnΛΥΛΡΛΛΛΤ ΠΘ(ΠΝ+n)/ΠΘ(ΠΝ) Λ»ΛΛΛΠΖΝΛ§ΛηΛ·Ϋ–ΛΤΛ≠ΛόΛΙΛ§,
Ξ§ΞσΞό¥ΊΩτΛΈ…ΗΫύ≈ΣΛ ά≠ΦΝ ΠΘ(x+1)=xΠΘ(x) ΛρΜ»ΛΠΛ», Λ≥ΛλΛœ
ΠΘ(ΠΝ+n)/ΠΘ(ΠΝ)
=(ΠΝ+n-1)ΠΘ(ΠΝ+n-1)/ΠΘ(ΠΝ)=..=(ΠΝ+n-1)(ΠΝ+n-2)..ΠΝΠΘ(ΠΝ)/ΠΘ(ΠΝ)
=(ΠΝ+n-1)(ΠΝ+n-2)..ΠΝ=
ΠΝ(n)
Λ«ΛΙΓΘ
ΛΙΛκΛ», œά ΗΛΈ(3)ΦΑΛΈ
p(z) =
ΠΑr(ΠΑo(ΠΝroΠΧro)(nro)) /ΠΝr(nr)
ΛœΦ¬Λœ, Ά≠Η¬ΦΓΗΒΛΈΨλΙγΛάΛ»
p(z) =
ΠΑrΠΘ(ΠΝr)/ΠΘ(ΠΝr+nr)ΠΑoΠΘ(ΠΝroΠΧro+nro)/ΠΘ(ΠΝroΠΧro)
Λ»ΛΛΛΠ, ΛηΛ·ΗΪ¥ΖΛλΛΩPolya §…έΛ«ΛΙΓΘ(4)(9)ΦΑΛβΖΝΦΑΛ»ΛΖΛΤΛœΤ±ΛΗΓΘ
ΦΪ §Λ«Τ≥Ϋ–ΛœΛΖΛΤΛΛΛ ΛΛΛ«ΛΙΛ§, (4)(9)ΛœΛ≥Λ≥ΛΪΛι≥δΛ»ΦΪΝ≥ΛΥΒαΛόΛξΛΫΛΠΛ«ΛΙΓΘ
œά ΗΛ«ΛœΛΒΛιΛΥ, Λ…ΛΠΛδΛΟΛΤType blockΛρΖηΛαΛκΛΪ, ΛΫΛΈΛΩΛαΛΈΞ«ΓΦΞΩΙΫ¬ΛΛœΛ…ΛΠΛΙ
ΛΌΛ≠ΛΪ, …―Ϋ–ΛΙΛκ… ΜλΛδΟ±Ηλ(theΛδ¥ßΜλΛ Λ…)ΛρΝ¥…τΙΆΈΗΛΙΛκΛ»ΗζΈ®Λ§Α≠ΛΛΛΈΛ«
Λ…ΛΠΕαΜςΛΙΛκΛΪ, ..Λ Λ…Λ§ΒΆΛαΙΰΛόΛλ, ΛΒΛιΛΥΦ¬Η≥Λ«ΛœHMM,USM(ΞφΞΥΞΑΞιΞύΛΈΡΕ¥ Ο±Λ
Ο±Ηλ §≥δΧδ¬ξ), PTSGΛΈ≥ΊΫ§Λ Λ…ΛΥ≈§Ά―ΛΖΛΤ..ΛόΛ«ΫώΛΪΛλΛΤΛΛΛόΛΙΓΘΤβΆΤ«ΜΛΙΛ°ΛκΓΘ
ΛΝΛ ΛΏΛΥ, Λ≥ΛΈ ΐΥΓΛœ¥πΥή≈ΣΛΥ±ΘΛλ ―ΩτΛ§ΤσΟΆΛΈΨλΙγΛΥΤΟΛΥΧρΈ©ΛΡΧδ¬ξΛ«
(Λ ΛΦΛ Λι,Γ÷±ΘΛλ ―ΩτΛρΛΛΛ·ΛΡflipΛΙΛκΛΪΓΉΛρΞΒΞσΞΉΞξΞσΞΑΛΙΛκΛΩΛα), §≥δΧδ¬ξΛΊΛΈ
≈§Ά―ΛœΦΪΝ≥Λ«ΛΙΛ§, HMMΛ«±ΘΛλΨθ¬÷Λ§2ΛηΛξ¬γΛ≠ΛΛΨλΙγΛœ
- ΗΫΚΏΞΒΞσΞΉΞκ¬–ΨίΛΈΨθ¬÷(ΈψΛ®Λ–4Λ»ΛΙΛκ)Λρ, ΦΓΛΥ≤ΩΛΥ ―Λ®ΛκΛΪΛρ 1..K ΛΪΛιUniform ΛΥΝΣΛ”,
- Ξ’ΞξΞΟΞΉΛΙΛκΛ»ΖηΛαΛΩΞιΞσΞάΞύΛ mΗΡΛρΛΫΛΈΨθ¬÷ΛΥ ―Λ®Λκ
Λ»ΛΛΛΠΝύΚνΛρΛΙΛκΛ», KΓΏKΛΈΝΪΑήΙ‘ΈσΛρΞΙΞιΞΛΞΙΞΒΞσΞΉΞξΞσΞΑ≈ΣΛΥΕ―ΑλΛΥΛ ΛαΛκ
Λ≥Λ»ΛΥΛ ΛκΛΩΛαok, ΛΈΛηΛΠΛ«ΛΙΓΘ
ΛΩΛά, ΟχΦ‘ΛœΫώΛΛΛΤΛΛΛ ΛΛΛ«ΛΙΛ§, Λ≥ΛλΛœKΛ§»φ≥”≈ΣΨ°ΛΒΛΛΜΰΛΥΛœΆ≠ΗζΛ«ΛΙΛ§,
±ΘΛλΨθ¬÷ΩτΛ§¬γΛ≠ΛΛΜΰΛΥΛœΛΪΛ Λξ»σΗζΈ®Λ ≤Ρ«Ϋά≠Λ§ΛΔΛκΛΈΛ«, ΛβΛΠΨ·ΛΖΗζΈ®≈ΣΛ MCMCΛ§
Λ≥ΛΈΨλΙγΛΥ≥»ΡΞΛ«ΚνΛλΛκΛΈΛΪΛβ, Λ»ΛΛΛΠΒΛΛ§ΛΖΛόΛΙΓΘ
*1: ΚΘΗΪΛΩΛι, Percy LiangΛΈ
ΞΎΓΦΞΗ
Λ«ΞΙΞιΞΛΞ…Λ§Ηχ≥ΪΛΒΛλΛΤΛΛΛκΛΈΛ«, ΛΫΛΝΛιΛβΗΪΛκΛ»Φψ¥≥ΛοΛΪΛξΛδΛΙΛ·Λ ΛκΛΪΛβ
ΟΈΛλΛόΛΜΛσΓΘ
*2: Λ≥ΛΈΛ≥Λ»ΦΪ¬ΈΛœΥΆΛβ≤ΩΛ»Λ Λ·ΜΉΛΟΛΩΛ≥Λ»Λ§ΛΔΛΟΛΩΓΘ
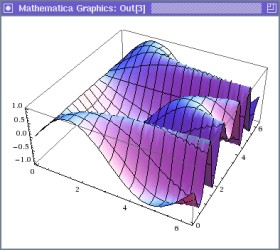
ΜΑΖνΛΈ«·≈ΌΥωΛΥ, ΆΫΜΜΛ§Ψ·ΛΖΆΨΛΟΛΩΛ»ΛΛΛΠΛ≥Λ»Λ«, Linux»«ΛΈ
MathematicaΛρ¬εΆΐ≈ΙΛΈ
ΤϋΥή≈≈Μ“ΖΉΜΜ
ΛΪΛιΙΊΤΰΛΖΛΤΝœΟΈΞΑΞκΓΦΞΉΛΈΖΉΜΜΒΓΛΥΞΛΞσΞΙΞ»ΓΦΞκΛΖΛόΛΖΛΩΓΘ
MathematicaΛΥΛœNotebookΞΛΞσΞΩΓΦΞ’ΞßΓΦΞΙΛ»ΛΛΛΠ…ΗΫύΛΈΞΛΞσΞΩΓΦΞ’ΞßΓΦΞΙΛ§
ΛΔΛΟΛΤ, »σΨοΛΥΛηΛ·Λ«Λ≠ΛΤΛΛΛκΛβΛΈΛΈ,
- ‘ΫΗΛΖΛΩΤβΆΤΛρΚΤΆχΆ―Λ«Λ≠Λ ΛΛ≈≈¬νΛΈΛηΛΠΛ ΛβΛΈ
- ΦΪΤΑΛ«ΞΛΞσΞ«ΞσΞ»ΛΖΛΤΛ·ΛλΛ ΛΛ(Ϋ≈ΆΉ)
- EmacsΞ–ΞΛΞσΞ…Λ§Μ»Λ®Λ ΛΛ
Λ Λ…, Φ¬ΚίΛΥΞΉΞμΞΑΞιΞύΛρΫώΛ·ΛΥΛœΜ»ΛΛΛΥΛ·ΛΛ≈άΛ§¬ΩΛΛΓΘ(ΛΈΛ«, ≤»ΛΈMacΨεΛΈ
MathematicaΛβΛ≥ΛΈΜ»ΛΛΛΥΛ·ΛΒΛΈΛΩΛα, ΛΔΛόΛξΜ»ΛΟΛΤΛΛΛ ΛΪΛΟΛΩΓΘ)
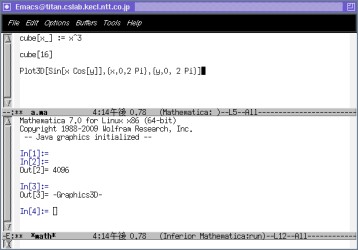
EmacsΛΪΛιΜ»Λ®Λ–Λ≥ΛΈΧδ¬ξΛœ≤ρΨΟΛΖΛόΛΙΛ§, math.el Λδmma.elΛœΟ±ΛΥmathΞ≥ΞόΞσΞ…Λρ
ΞΖΞßΞκΛ»Τ±ΛΗΛηΛΠΛΥΤΑΛΪΛΙΛάΛ±ΛΪ, *.m Ξ’ΞΓΞΛΞκΛρ ‘ΫΗΛΙΛκΛΩΛαΛΈΞβΓΦΞ…Λ«,
cmuscheme.el
ΛΈΛηΛΠΛΥΞΉΞμΞΑΞιΞύΛρΫώΛ≠Λ Λ§ΛιΦΑΛρΫγΦΓ…Ψ≤ΝΛΙΛκ, Λ»ΛΛΛΠΛηΛΠΛ
Λ≥Λ»Λ§Λ«Λ≠Λ ΛΛΓΘ
Λ ΛΛΛ ΛιΚνΛλ, Λ»ΛΛΛΠX68ΞφΓΦΞΕΛΈάΚΩάΛ«(Λ»ΛΛΛΠΛέΛ…Λ«ΛœΛ ΛΛΛ«ΛΙΛ§),
NakaiΛΒΛσΛ§2003«·ΛΥ≤ΰΈ…ΛΒΛλΛΩ
math.el
ΛΥΛΒΛιΛΥΡ…≤ΟΛΖΛΤ, "inferior Mathematica"ΞβΓΦΞ…ΛρΡσΕΓΛΙΛκ math++.el
Λ»ΛΛΛΠelispΛρ¥ Ο±ΛΥΫώΛΛΛΤΛΏΛΩΓΘ
ΨεΛΈ≤ηΝϋΛΈΛηΛΠΛΥ, Ξ≥ΓΦΞ…ΛρΫώΛ≠Λ Λ§Λι C-cC-e (or C-cC-s)Λ«ΚΘΛΈΦΑΛρMathematicaΛΥ
ΝςΛξ, C-cC-r Λ«ΞξΓΦΞΗΞγΞσΛρ¥ίΛ¥Λ»ΝςΛλΛόΛΙΓΘ
MathematicaΛœLispΛ»ΑψΛΟΛΤΦΑΛΈΕ≠≥ΠΛ§έΘΥφΛ ΛΈΛ«, ΕθΙ‘Λ«ΕηάΎΛιΛλΛΩ…τ §Λ§
ΑλΛΡΛΈΦΑΛάΛ»ΛΖΛΤΛΛΛόΛΙΓΘ
Λ≥ΛλΛœ scheme ΛρemacsΛ«Μ»ΛΠΛΈΛ»ΛέΛ»ΛσΛ…Τ±ΛΗΛ«(Λ»ΛΛΛΠΛΪ, MathematicaΛœΥήΦΝ≈ΣΛΥ
LispΛ«ΛΙΛ§), ΛΪΛ ΛξΞΉΞμΞΑΞιΞύΛ§ΫώΛ≠ΛδΛΙΛ·Λ ΛξΛόΛΖΛΩΓΘ
Ηχ≥ΪΛΖΛ ΛΛΛ»Λ…ΛΠΛβΡΨΛΙΒΛΛ§ΛΖΛ ΛΛΛΈΛ«, ¥ Ο±ΛΥ
Ηχ≥ΪΛΖΛΤ
ΛΣΛ≠ΛόΛΙΓΘ
 -
-
Λ ΛΣ, Mathematica Λ«ΛœΞΑΞιΞ’ΞΘΞΟΞ·ΞΙΛ§ΡΕΫ≈ΆΉΛ«ΛΙΛ§, math Ξ≥ΞόΞσ΅˸ΫΒΩΞκΞ»
Λ«Λœ≤ηΝϋΛ§Ϋ–ΛόΛΜΛσΓΘΧδΛΛΙγΛοΛΜΛΩΛ»Λ≥Λμ, init.m Λ Λ…Λ« <<JavaGraphics` Λ»ΛΖΛΤ
JavaGraphics ΛρΞμΓΦΞ…ΛΖΛΤΛΣΛ·Λ», ΨεΛΈΛηΛΠΛΥ ΧΝκΛ«≤ηΝϋΛ§Ϋ–ΛκΛηΛΠΛ«ΛΙΓΘ