БӘөуӨО·лІМӨПӨИӨвӨ«ӨҜ, ҪӘО»ёеӨЛ
NHKӨОі«ЙјВ®Ку
Өтё«ӨЖөӨЙХӨӨӨҝӨіӨИӨП, ҘкҘуҘҜАиӨОҘЪЎјҘёӨЗ°мИЦІјӨОЎЦі«ЙјҪкЎЧӨтҘҜҘкҘГҘҜӨ·Өҝ»юӨЛёҪӨмӨл, ¶иӨҙӨИӨОЕкЙј·лІМӨ¬Ө«ӨКӨк°ЫӨКӨлӨИӨӨӨҰӨіӨИӨЗӨ·ӨҝЎЈ
ӨҝӨИӨЁӨР, »дӨОЕкЙјӨ·Өҝ№Б¶иӨЗӨПіӨП·Я·НіөӘ»бӨ¬2°МӨЗ11.3%ӨОЖАЙјОЁӨ¬ӨўӨлӨОӨЛВРӨ·,
ҝ·ҪЙ¶иӨЗӨП5°МӨЗ9.2%ӨЛӨ№Ө®ӨЮӨ»ӨуЎЈ°мКэӨЗ№Б¶иӨЗӨП»іЕәВу»бӨП6°МӨЗ8.2%ӨКӨОӨЛВРӨ·,
ҝ·ҪЙ¶иӨЗӨП2°МӨЗ, 11.8%ӨвӨОЖАЙјОЁӨ¬ӨўӨкӨЮӨ№ЎЈ
ГжМо¶иӨЗӨП, ¶Ұ»әЕЮӨО»іЕәВу»бӨ¬ј«МұЕЮӨОД«Жь·тВАПә»бӨтИҙӨӨӨЖ1°МӨЛӨКӨГӨЖӨӨӨЮӨ№ЎЈ
°мИЦӨпӨ«ӨкӨдӨ№ӨӨӨОӨП, ёшМАЕЮӨОГЭГ«ӨИӨ·»Т»бӨ¬ВзЕД¶и, ЛМ¶и, ИД¶¶¶и, №УАо¶и, И¬ІҰ»Т»ФӨКӨЙӨЗӨП1°МӨЛӨКӨГӨЖӨӨӨлӨИӨӨӨҰӨіӨИӨЗӨ·ӨзӨҰЎЈ
¶иӨАӨұӨЗӨКӨҜ»ФЙфӨдОҘЕзӨЛӨвВзӨӯӨК°гӨӨӨ¬ӨўӨк, ҝАДЕЕзӨд»°ВрЕзӨЗӨПАё°р№ё»Т»бӨ¬°өЕЭЕӘӨКЖАЙјӨЗ1°М, ҫ®іЮё¶ВјӨЗӨП»іЛЬВАПә»бӨ¬1°МӨЛӨКӨГӨЖӨӨӨЮӨ№ЎЈ
ӨіӨмӨП, ӨўӨлДшЕЩӨПҪкЖАӨдҙрИЧГП°и(БПІБіШІсӨ¬ВҝЛаГП°иӨЛВзӨӯӨКҙрИЧӨт»эӨГӨЖӨӨӨлӨКӨЙ)ӨЗАвМАӨЗӨӯӨЮӨ№Ө¬, 2°М°К№ЯӨвҙЮӨбӨлӨИ, »Ф¶иӨОҙЦӨЛӨПӨ«ӨКӨк»чӨЖӨӨӨлӨвӨО,
ӨўӨлӨӨӨП°гӨҰӨвӨОӨ¬ӨўӨк, БӘөу·лІМӨ«ӨйЕэ·ЧЕӘӨЛГП°иӨОЖГД§Ө¬ё«ӨЁӨЖӨӯӨҪӨҰӨЗӨ№ЎЈ
ӨҪӨіӨЗ, ҫеӨОҘЪЎјҘёӨ«ӨйіЖ»ФД®ВјӨОБӘөу·лІМӨтҘЖҘӯҘ№ҘИӨЛҘіҘФҘЪӨ·,
PythonӨЗҘСЎјҘәӨ·ӨЖҘЗЎјҘҝӨтәоӨк, Еэ·ЧЕӘӨЛК¬АПӨ·ӨЖӨЯӨЮӨ·ӨҝЎЈ
*1
 ЕкЙјОЁӨО°гӨӨ
ЕкЙјОЁӨО°гӨӨ
ӨіӨҰӨӨӨГӨҝҫм№зӨЛӨП, ЕкЙјОЁӨҪӨОӨвӨОӨЗӨПӨКӨҜ, іЖ»ФД®ВјӨОЕкЙјОЁӨО, БҙВОӨОЕкЙјОЁ(56.55%)ӨЛВРӨ№ӨлИжОЁӨтё«ӨлӨОӨ¬НӯёъӨЗӨ№ЎЈ *2 ИжӨ¬1ӨЗӨўӨмӨРБҙВОӨИЖұӨёӨИӨӨӨҰӨіӨИӨЗӨ№ӨОӨЗ, ВРҝфӨтӨИӨмӨР, ИжӨ¬1ӨОӨИӨӯӨЛГНӨП0ӨЛӨКӨкӨЮӨ№ЎЈ ГП°и a ӨЗӨОЕкЙјОЁӨт p(v|a), БҙВОӨЗӨОЕкЙјОЁӨт p(v) (=0.5655) ӨИӨӘӨҜӨИ, ӨіӨмӨП log p(v|a)/p(v) Өт·Ч»»Ө№ӨлӨіӨИӨЛӨКӨкӨЮӨ№ЎЈӨіӨмӨтҘЧҘнҘГҘИӨ·ӨҝӨвӨОӨ¬°КІјӨЗӨ№ЎЈ
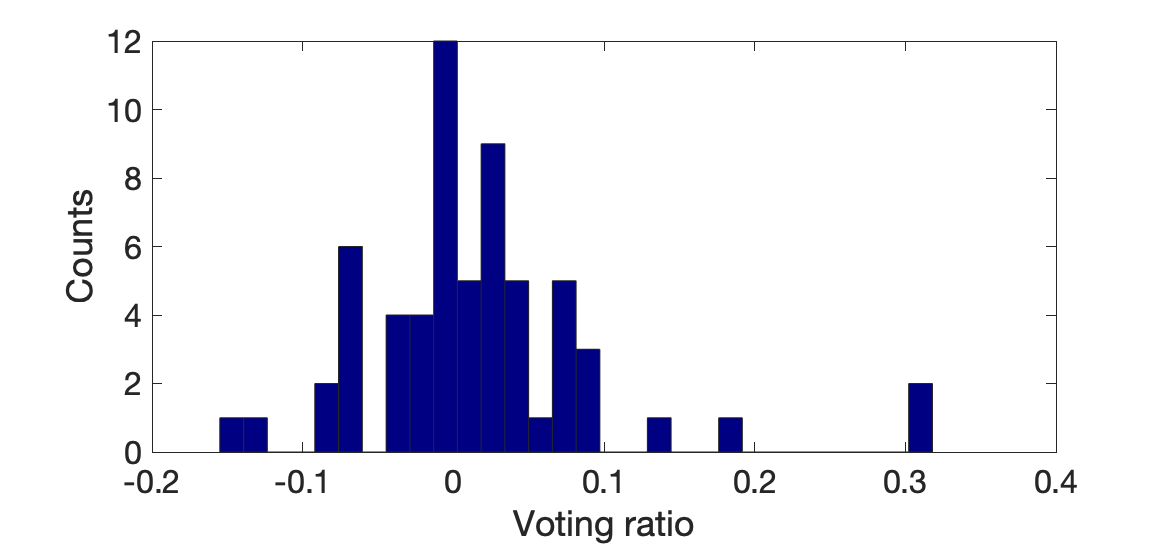
ЎЦ»Ф¶иҘЩҘҜҘИҘлЎЧӨИБкёЯҫрКуОМ
ҫеӨОҘЩҘҜҘИҘлӨОӨЮӨЮӨЗӨвГП°иӨОЖГД§ӨПЙҪӨ»ӨЮӨ№Ө¬, word2vec ӨИЖұННӨЛ, ӨіӨмӨт јЎёө°өҪМӨ№ӨлӨіӨИӨЗ, ҫрКуӨтӨиӨкҘіҘуҘСҘҜҘИӨЛ¶ЕҪМӨ·ӨҝҘЩҘҜҘИҘлӨтЖАӨлӨіӨИӨ¬ӨЗӨӯӨЮӨ№ЎЈ¶сВОЕӘӨЛӨП, PMI(a,c) ӨтҪДІЈӨЛКВӨЩӨҝ№ФОуӨт X ӨИӨӘӨҜӨИ,
X = USVT = (U√S)(V√S)T
ӨИXӨтЖГ°ЫГНК¬ІтӨ·ӨЮӨ№ЎЈӨіӨОӨИӨӯ, UўеSӨӘӨиӨУVўеSӨОіЖОуӨ¬, ГП°иӨӘӨиӨУёхКдјФӨтЙҪӨ№ҘЩҘҜҘИҘлӨЛӨКӨкӨЮӨ№ЎЈӨіӨОЖвАСӨ¬ВзӨӯӨұӨмӨР, ёөӨОҘЗЎјҘҝӨЗPMIӨОГНӨ¬ВзӨӯӨӨ, ӨДӨЮӨкӨҪӨОГП°иӨИӨҪӨОёхКдјФӨОБкҙШӨ¬ВзӨӯӨӨӨіӨИӨт°ХМЈӨ·ӨЖӨӨӨлӨпӨұӨЗӨ№ЎЈЖГӨЛ, ЖГ°ЫГНК¬ІтӨЗҫе°М2ёДӨОёЗНӯГНӨӘӨиӨУёЗНӯҘЩҘҜҘИҘлӨтӨИӨмӨР, әЗӨв°гӨӨӨОВзӨӯӨКДҫётӨ№Өл2јЎёөӨЗ»Ф¶иҘЩҘҜҘИҘлӨтІД»лІҪӨ№ӨлӨіӨИӨ¬ӨЗӨӯӨЮӨ№ЎЈ ӨіӨмӨт№ФӨГӨҝӨОӨ¬ІјӨОҝЮӨЗӨ№ЎЈ(ҘҜҘкҘГҘҜӨЗіИВз)
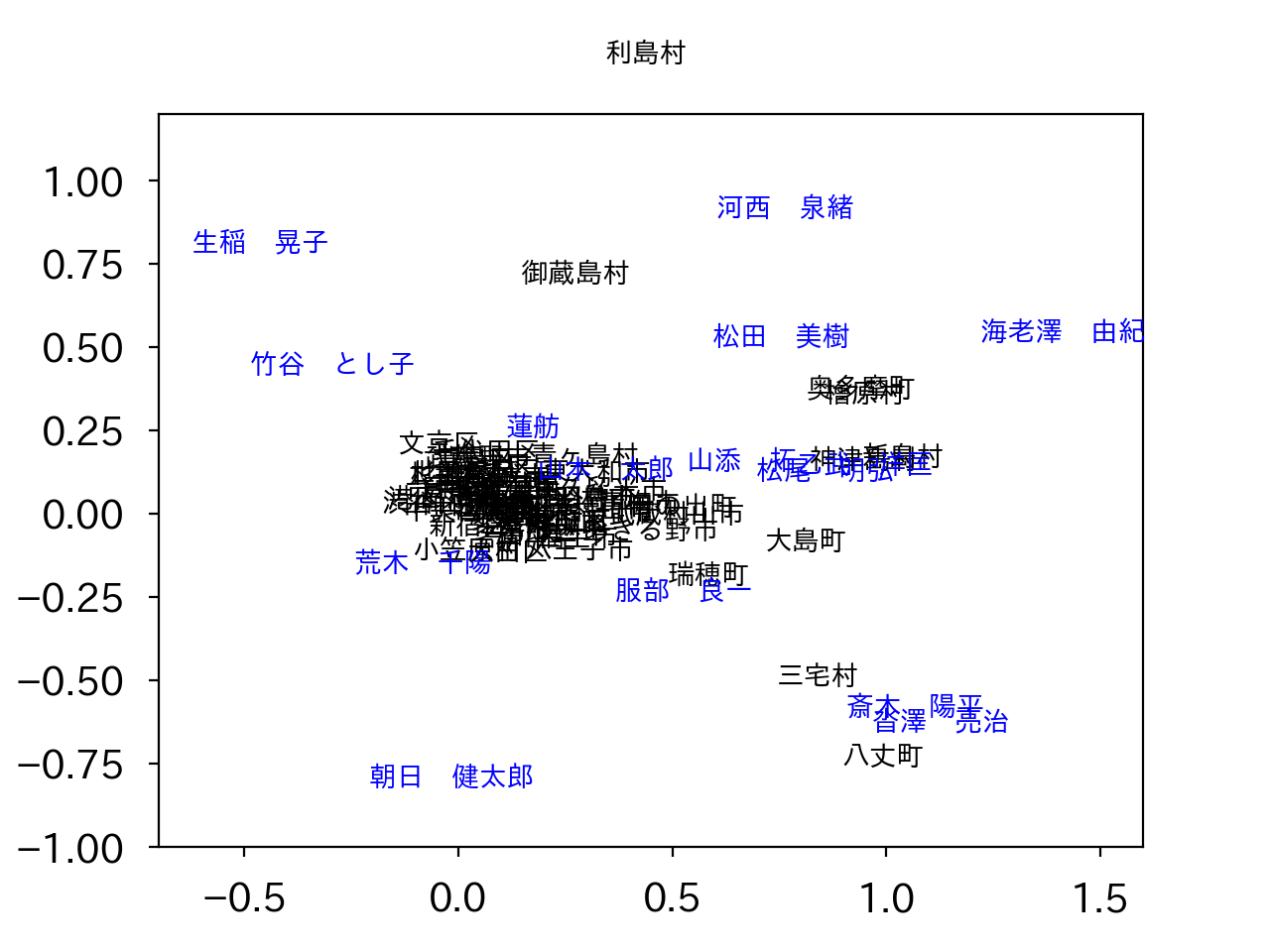
ҫеӨОҝЮӨПГжҝҙЙфӨЛҘЩҘҜҘИҘлӨ¬ҪёГжӨ·ӨЖӨӨӨЮӨ№ӨОӨЗ, іИВзӨ·ӨҝӨвӨОӨ¬ІјӨОҝЮӨЗӨ№ЎЈ (ҘҜҘкҘГҘҜӨЗіИВз)
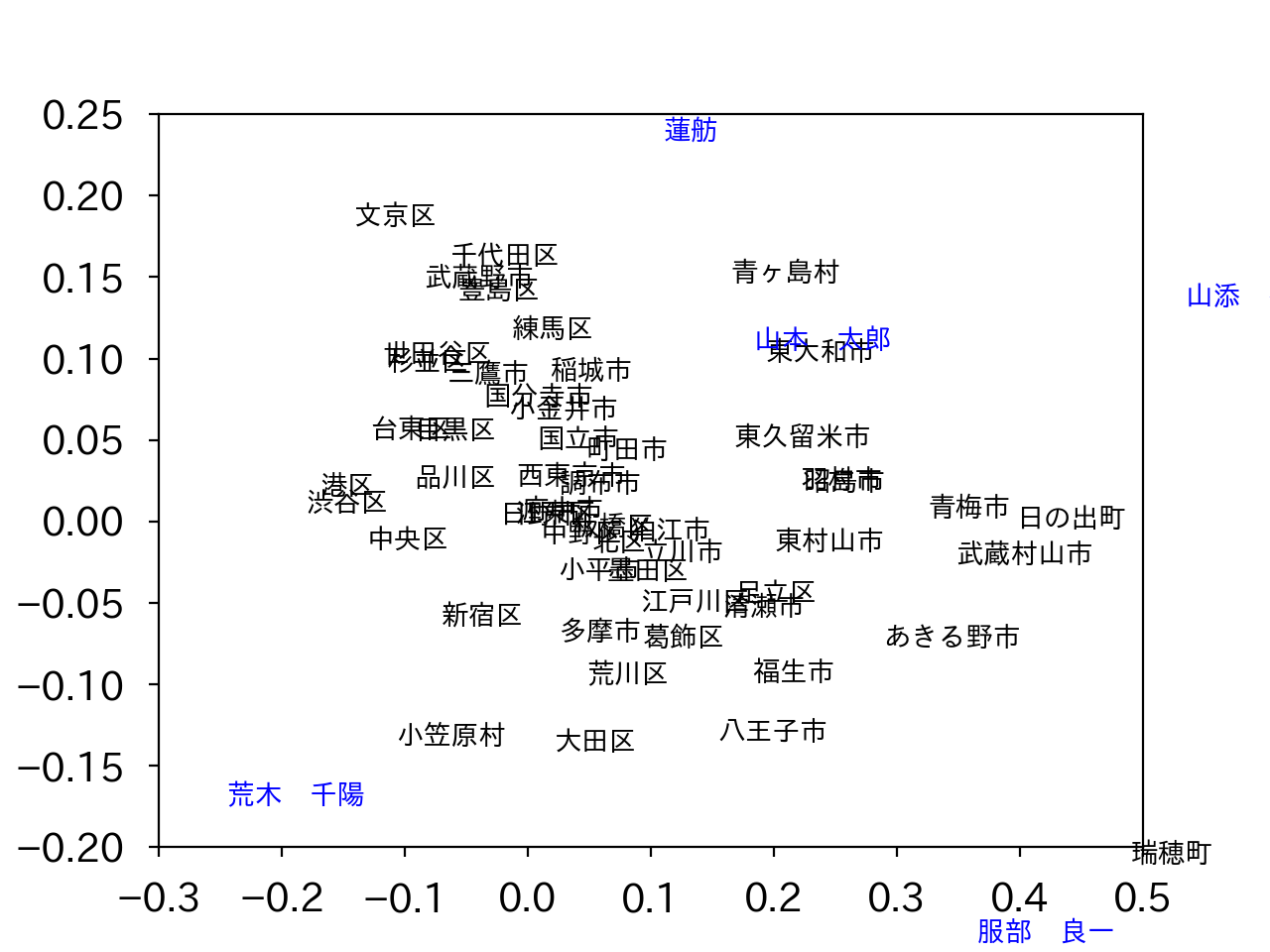
ӨіӨОІД»лІҪӨП, ӨўӨҜӨЮӨЗәЗҪйӨО2ёДӨОёЗНӯҘЩҘҜҘИҘлӨтНСӨӨӨҝӨвӨОӨЗ, 3ёДМЬ°К№ЯӨЛӨПӨвӨГӨИНӯұЧӨКҫрКуӨ¬ұЈӨмӨЖӨӨӨлІДЗҪАӯӨ¬ӨўӨкӨЮӨ№ЎЈ3ёДӨОёЗНӯҘЩҘҜҘИҘлӨтНСӨӨӨмӨР, ҘЩҘҜҘИҘлӨт3јЎёөӨЛҘЧҘнҘГҘИӨ№ӨлӨіӨИӨ¬ӨЗӨӯӨЮӨ№ЎЈ ӨіӨмӨт№ФӨГӨҝӨвӨОӨ¬ІјӨОҝЮӨЗӨ№ЎЈ
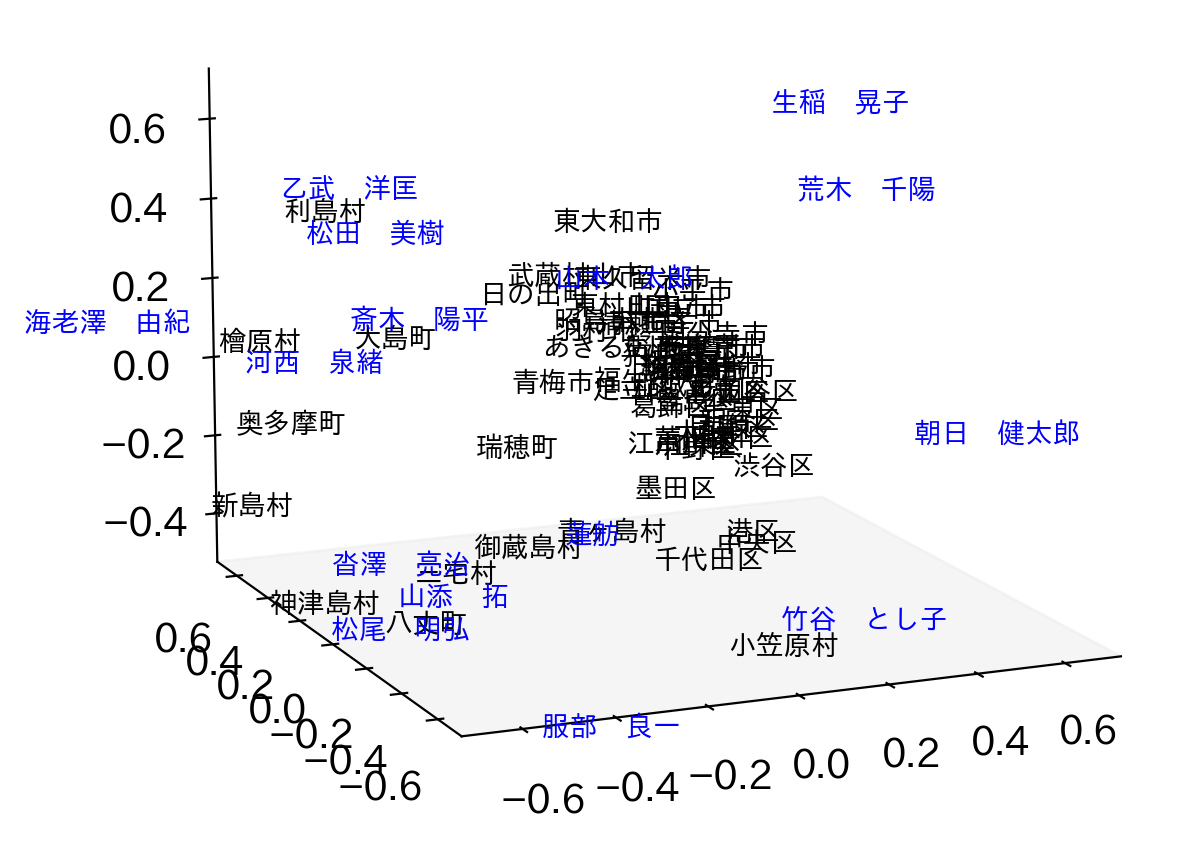
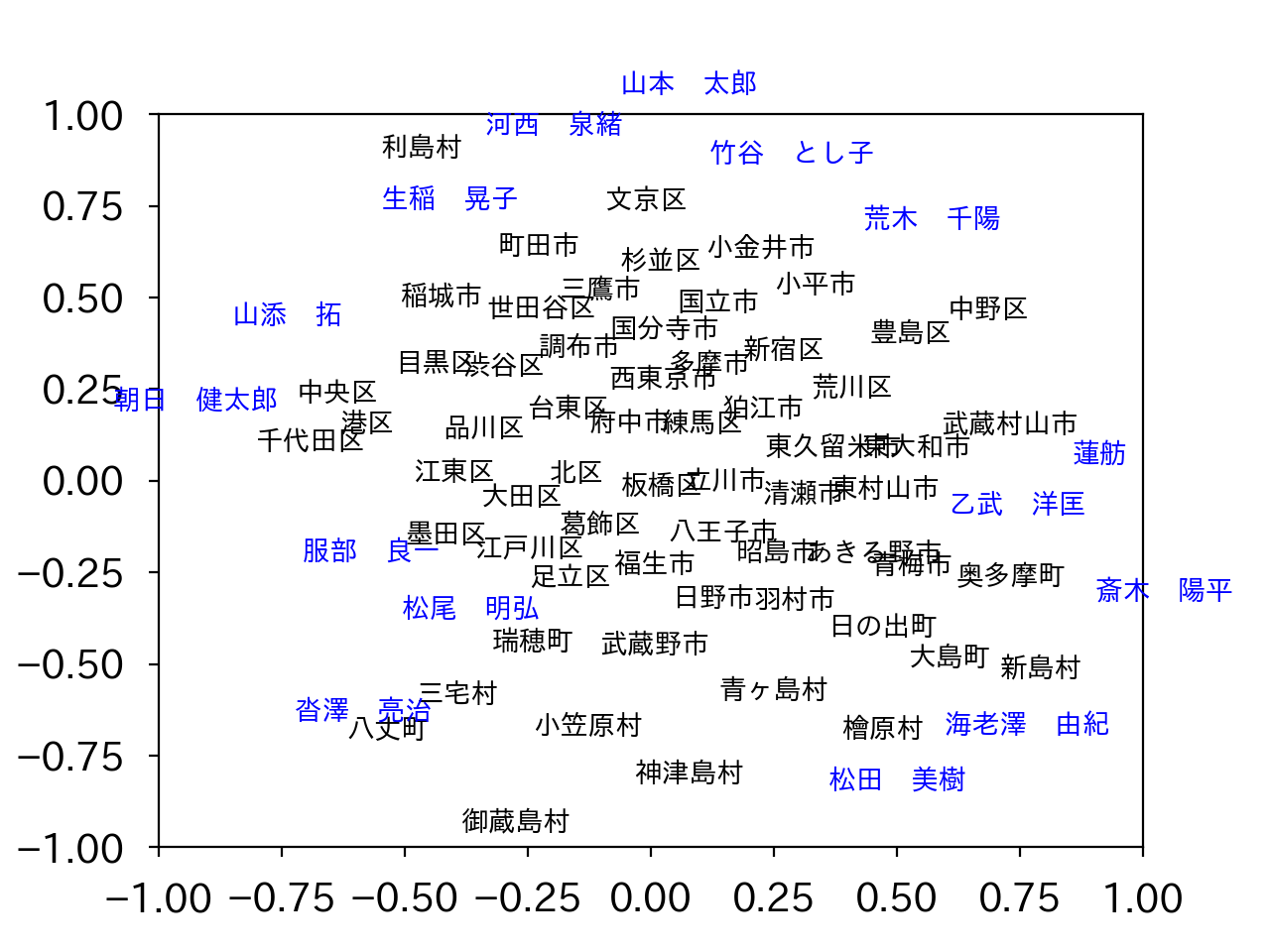
ӨКӨӘ, ҫеӨОК¬АПӨП, Ө№ӨЩӨЖӨОёхКдјФ34ҝНӨОҫрКуӨтЕщІБӨЛНСӨӨӨлӨИ, ЛўЛчёхКдӨО°мГЧӨ¬ЙФЙ¬НЧӨЛ№вӨҜЙҫІБӨөӨмӨЖӨ·ӨЮӨҰӨҝӨб, ЖАЙјҝфҫе°М15ҝНӨОҘЗЎјҘҝӨтНСӨӨӨЖӨӨӨЮӨ№( (PMI(a,c1),ЎД,PMI(a,c15) )ӨтјВәЭӨОЖГД§ҘЩҘҜҘИҘлӨЛӨ·ӨЖӨӨӨЮӨ№)ЎЈӨіӨОГНӨтКСӨЁӨлӨИ·лІМӨ¬КСӨпӨлӨҝӨб, PMI(a,c)ӨтӨҪӨОёхКдјФӨОЖАЙјіООЁp(c)ӨЗҪЕӨЯӨЕӨұӨлӨіӨИӨ¬№НӨЁӨйӨмӨЮӨ№Ө¬, ӨҪӨҰӨ№ӨлӨИword2vecӨИӨОВРұюҙШ·ёӨ¬ӨКӨҜӨКӨлӨҝӨб, ГұёмҘЩҘҜҘИҘлӨЛҙШӨ·ӨЖГОӨйӨмӨЖӨӨӨлННЎ№ӨКНэПАЕӘӨКАӯјБӨ¬КЭҫЪӨөӨмӨлӨ«ӨЙӨҰӨ«ӨЛӨДӨӨӨЖӨП, ёЎҫЪӨ¬Й¬НЧӨЛӨКӨкӨҪӨҰӨЗӨ№ЎЈ
ӨКӨӘ, К¬АПӨЛНСӨӨӨҝҘЗЎјҘҝӨӘӨиӨУPythonҘ№ҘҜҘкҘЧҘИӨП, Ө№ӨЩӨЖGithubӨОҘмҘЭҘёҘИҘк https://github.com/daiti-m/tokyo2022 ӨЛӨЖёші«Ө·ӨЖӨӨӨЮӨ№ЎЈ
*2: ЕкЙјОЁӨПіООЁӨЗӨ№Ө¬, іООЁӨОВРҝфӨПҫрКуОМӨИӨ·ӨЖӨО°ХМЈӨт»эӨБӨЮӨ№Ө«Өй, ҫрКуОМӨО°ъӨӯ»»Өт№ФӨГӨЖә№Өтё«ӨлӨіӨИӨП, іООЁӨОИжӨт·Ч»»Ө·ӨЖӨ«ӨйВРҝфӨтӨИӨлӨіӨИӨИЕщІБӨЛӨКӨкӨЮӨ№ЎЈ