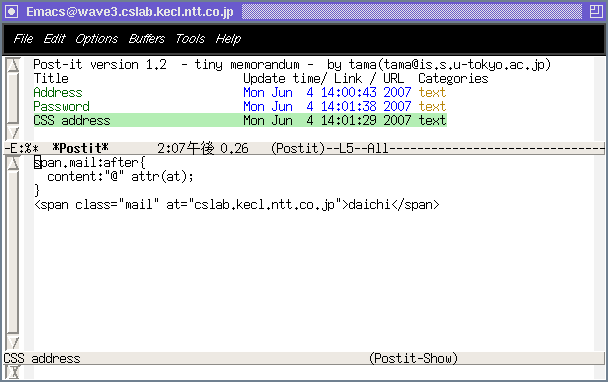
#1
Postit.el(TM)
ΖΉΜΜΒΓΨεΛ«≤ΩΛΪΛΝΛγΛΟΛ»ΛΖΛΩΞαΞβΛρΦηΛξΛΩΛΛΛ»Λ≠, WindowsΛ« κΛιΛΖΛΤΛΛΛκΩΆΛœ
Μφcopi(Lite)
ΛρΜ»Λ®Λ–ΛΛΛΛΛΈΛ«ΛΙΛ§, UnixΛ«ΛœΜ»Λ®ΛόΛΜΛσΓΘ
Α―ΚΌΛΪΛόΛοΛΚChangeLogΞαΞβΛΥΝ¥…τΫώΛΛΛΤΛΖΛόΛΠΛ»ΛΛΛΠΦξΛβΛΔΛξΛόΛΙΛ§,
ΗΓΚςΛΙΛκ…§ΆΉΛ§ΛΔΛκΛΈΛ«, ΒΜΫ―≈ΣΛ ΞαΞβΛœΛΫΛλΛάΛ±ΛόΛ»ΛόΛΟΛΤΛΛΛκΛ» ΊΆχΛάΛ»
¥ΕΛΗΛκΛ≥Λ»Λ§ΛΔΛξΛόΛΙΓΘ
ATRΛΥΑήΛΟΛΤΛΪΛι, ΒΜΫ―ΞαΞβΛœ≈§≈ωΛ Ξ’ΞΓΞΛΞκΛΥΫώΛ≠¬≠ΛΖΛΤΛΛΛΩΛΈΛ«ΛΙΛ§,
ΛΫΛμΛΫΛμΗ¬≥ΠΛρ¥ΕΛΗΛΤΛ≠ΛΩΛΈΛ«, ¥ΡΕ≠Λ§ΩΖΛΖΛ·Λ ΛΟΛΩΛΈΛρΒΓ≤ώΛΥ, άΈΜ»ΛΟΛΤΛΛΛΩ
postit.el ΛΥΧαΛΖΛΤΛΏΛόΛΖΛΩΓΘ
Postit.el(ΨεΛΈ≤ηΝϋΓΘΞ·ΞξΞΟΞ·Λ«≥»¬γ) ΛœάΈΛΥΕΧ±έΖ·Λ§ΫώΛΛΛΤ,
NAISTΛΥΛΛΛΩΜΰΛœΥΆΛβΛΚΛΟΛ»Μ»ΛΟΛΤΛΛΛΩΛβΛΈΛ«ΛΙΛ§,
EmacsΛΈΞ–ΓΦΞΗΞγΞσΛ§ΨεΛ§ΛΟΛΩΛΈΛ«Μ»Λ®Λ ΛΛΛΪΛ»ΜΉΛΛΙΰΛσΛ«ΛΛΛΩΛι
ΛΫΛΈΛόΛό ―ΙΙΛ ΛΖΛΥΤΑΛ·Λ≥Λ»Λρ»·ΗΪΓΘΛαΛΝΛψΛαΛΝΛψΞαΞβΛ§Μ»ΛΛΛδΛΙΛ·Λ ΛξΛόΛΖΛΩΓΘ
m Λ«ΞαΞβΛρΫώΛΛΛΩΛξ, Ξ’ΞΓΞΛΞκΛδURLΛΥΞξΞσΞ·ΛρΡΞΛΟΛΩΛξ, ΛΫΛλΛιΛρΗΓΚςΛΖΛΩΛξΛΙΛκ
ΛΈΛ§EmacsΛΪΛι¥ Ο±ΛΥΛ«Λ≠ΛόΛΙΓΘ
ΨεΛΈEmacsΛœΡΧΨοΛΈFedora CoreΛΈΛβΛΈΛ«, Ξ–ΓΦΞΗΞγΞσΛœ21.4Λ«ΛΙΓΘ
Postit.elΛρΛΑΛΑΛκΛ»,
≤ΰΡϊ»«
Λ§Ο÷ΛΛΛΤΛΔΛκ
ΧΛΈ ΐΛΈΞΎΓΦΞΗ
Λ§Ξ“ΞΟΞ»ΛΖΛόΛΙΛ§, Λ≥ΛΝΛιΛΈΩΖΛΖΛΛ»«Λ«Λœ .postit ΛΈΞ’Ξ©ΓΦΞόΞΟΞ»Λ§SΦΑΛΥ
Λ ΛΟΛΤΛΛΛΤ, ΛδΛδ…‘Α¬(ΞΪΞΟΞ≥Λ§ΆνΛΝΛκΛ»¬γ ―Λ»ΛΪ, ΗΜζ≤ΫΛ±ΛΖΛΩΛξΛΖΛΩ)
Λ ΛΈΛ«, ΝΑΛΈΞ–ΓΦΞΗΞγΞσΛΈ1.2Λ§ΗΡΩΆ≈ΣΛΥΛœΛΣΛΙΛΙΛαΛ«ΛΙΓΘ
ΝΑΞ–ΓΦΞΗΞγΞσΛœ
Λ≥Λ≥ΛΈΞΎΓΦΞΗ
ΛΥΟ÷ΛΛΛΤΛΔΛξΛόΛΙΛ§(webarchiveΥϋΚ–), ΥϋΑλΛ ΛΛΨλΙγΛœ
Λ≥Λλ
ΛρΜ»ΛΟΛΤΛβOKΛ«ΛΙΓΘ
.emacs ΛΥ,
(autoload 'postit "postit" nil t)
(define-key ctl-x-map "p" 'postit)
Λ»ΫώΛΛΛΤΛΣΛ·ΛάΛ±Λ«, C-x p Λ«¥ Ο±ΛΥΞαΞβΛ§Μ»Λ®ΛόΛΙΓΘ
postit-1.2.tar.gz ΛΈΟφΛΥΞόΞΥΞεΞΔΞκΛ§¥όΛόΛλΛΤΛΛΛκΛΈΛ«, Μ»ΛΛ ΐΛœΛΫΛλΛρΗΪΛλΛ–
okΛ«ΛΙΓΘ
#2
PPMΛ»ΗάΗλΞβΞ«Ξκ (2)
≤§ΧνΗΕΖ·Λ§ΫώΛΛΛΤΛΛΛκ
ΛηΛΠΛΥPPMΛρCRPΛ»ΛΖΛΤ≤ρΦαΛ«Λ≠Λ ΛΛΛΪΛ»ΛΛΛΠœΟΛœ, MacKayΛΈΛ»Λ≥ΛμΛΥΛΛΛκ
Phil Cowans
(
Dasher
ΛρΦ¬ΝθΛΖΛΩΛΈΛœ»ύΛιΛΖΛΛ)ΛΈDœά
"Probabilistic Document Modeling"
ΛΥΛΔΛκΛΈΛρΜΉΛΛΫ–ΛΖΛΩΛΈΛ«, (ΚΌΛΪΛ·Ν¥ΛΤΤ…ΛσΛ«ΛΛΛκΜΰ¥÷ΛœΛ ΛΛΛΈΛ«ΛΙΛ§)
ΛΕΛΟΛ»Τ…ΛσΛ«ΛΏΛΩΓΘ
ΖκœάΛΪΛιάηΛΥΗάΛΠΛ», PPM-AΛœHDPΛΈΕαΜςΛ«, PPM-BΛ»PPM-DΛœKneser-Ney(ΛΡΛόΛξ
Pitman-Yor)ΛΈΤΟ ΧΛ ΨλΙγΛ«ΛΙΓΘ
PPMΛœWitten-Bell+Katz' Back-offΛ«ΛΙΛ§, Witten-BellΞΙΞύΓΦΞΗΞσΞΑΛœ
HDPΛΈΤΟ ΧΛ ΨλΙγΛ«ΛΙΓΘ
Λ…ΛΠΛΛΛΠΛ≥Λ»ΛΪΛ»ΛΛΛΠΛ», HDPΛ«Λœ≥Τ ΗΧ°Λ«ΨοΛΥΩΖΛΖΛΛΗλΛ§Base measureΛΪΛιΫ–ΗΫΛΙΛκ
≤Ρ«Ϋά≠Λ§ΛΔΛξΛόΛΙΛ§, Λ≥ΛλΛœΫ≈ ΘΛρΒωΛΖΛΤΛΛΛκΛΩΛα, Base measureΛΪΛιΛ≥ΛλΛόΛ«Λ»
Τ±ΛΗΗλΛ§ΞΒΞσΞΉΞκΛΒΛλΛκ≤Ρ«Ϋά≠Λ§ΛΔΛξΛόΛΙΓΘΛ≥ΛλΛ§Β·Λ≥ΛιΛ ΛΛ(HPYLMΛΈΗάΆ’Λ«ΗάΛΠΛ»,
tuw=1)ΛΈΨλΙγΛœ, HDPΛΈΞΙΞύΓΦΞΗΞσΞΑΛœWitten-BellΛ»≈υΛΖΛ·Λ ΛξΛόΛΙΓΘ
ΛΒΛΤΦ¬ΚίΛΥΛœ, HDPΛœ0-gramΛόΛ«ΚΤΒΔ≈ΣΛΥ≥ΈΈ®ΛρΚ°ΙγΛΙΛκΛΈΛΥ¬–ΛΖ,
PPMΛœΗΪΛΡΛΪΛΟΛΩΚ«ΡΙΛΈ ΗΧ°ΛρΜ»ΛΠΛ»ΛΛΛΠ≈άΛΥΑψΛΛΛ§ΛΔΛξΛόΛΙΓΘ
Λ≥ΛΈΛΩΛαΛΥPPMΛ«ΛœExclusionΛ»ΛΛΛΠ ΐΥΓΛρΜ»ΛΛΛόΛΙΛ§, Λ≥ΛλΛœKatz' Back-off
Λ»Τ±ΛΗΛ«ΛΙΓΘ
ΛφΛ®ΛΥ, Λ≥ΛλΛ§HDPΛΈΚΤΒΔ≈ΣΛ Κ°ΙγΛ»Λ…ΛΠΑψΛΠΛΈΛΪΛ»ΛΛΛΠΛΈΛ§Χδ¬ξΛ»Λ ΛκΛοΛ±Λ«ΛΙΛ§,
ΨεΛΈCowansΛΈDœάΛ«ΛœΛ≥ΛλΛρΦ¬ΚίΛΥΡ¥ΛΌΛΤ, PPM(ΛΡΛόΛξ, Witten-Bell+Katz' Back-off)
ΛœHDPΛΈΛΪΛ ΛξΈ…ΛΛΕαΜςΛΥΛ ΛΟΛΤΛΛΛκ, Λ»ΛΛΛΠΖκœάΛΥΟΘΛΖΛΤΛΛΛόΛΙΓΘ
Εώ¬Έ≈ΣΛΥΗάΛΠΛ», ΕαΜςΛΈΕώΙγΛœHDPΛΈconcentrationΞ―ΞιΞαΓΦΞΩΠΝΛΈΟΆΛΥΛηΛξΛόΛΙΛ§,
Λ≥ΛλΛ§≈ΒΖΩ≈ΣΛ ΟΆ(5ΓΝ10Λ·ΛιΛΛ)ΛΈ¥÷ΛœΛέΛ»ΛσΛ…ΑψΛΛΛ§Λ Λ·, ΛΫΛλΛηΛξΠΝΛ§¬γΛ≠Λ·Λ ΛκΛ»
»υΧ·ΛΥHDPΛΈ ΐΛ§Έ…Λ·Λ Λκ(ΛΒΛιΛΥΠΝΛ§¬γΛ≠Λ·Λ ΛκΛ», ExclusionΛρΙ‘ΛοΛ ΛΛ ΐΛ§ΕαΜςΛ§
Έ…Λ·Λ Λκ)Λ»ΛΛΛΠΖκ≤ΧΛΥΛ ΛκΛηΛΠΛ«ΛΙΓΘ
Αλ ΐ, PPM-BΛ»PPM-DΛœΛΫΛλΛΨΛλ, Kneser-NeyΛ«Ξ«ΞΘΞΙΞΪΞΠΞσΞ»ΖΗΩτdΛ§
1.0Λ»0.5ΛΈΤΟ ΧΛ ΨλΙγΛ«ΛΙΓΘ
Pitman-YorΛΈΗάΆ’Λ«ΗάΛΠΛ», Π»Λ§0Λ«, dΛ§1.0ΛόΛΩΛœ0.5, ΛΪΛΡΨεΛ«ΫώΛΛΛΩΛηΛΠΛΥ,
tuwΛ§ΨοΛΥ1Λ«ΛΔΛκΛηΛΠΛ (Λ≥ΛλΛ§K-NΛ§ΕαΜςΛ«ΛΔΛκΆΐΆ≥), Pitman-Yor≤αΡχΛΈΤΟ ΧΛ ΨλΙγΛ«ΛΙΓΘ
≤§ΧνΗΕΖ·ΛΈΞ®ΞσΞ»ΞξΛρΚ«ΫιΛΥΤ…ΛσΛάΜΰΛΥ, Λ≥ΛλΛœKneser-Ney(=Pitman-Yor)ΛάΛμΛΠΛ»
Ξ―ΞΟΛ»ΜΉΛΟΛΩΛΈΛ«ΛΙΛ§, Π»Λβ0ΛΥΛ ΛΟΛΤΛΛΛκΤΟ ΧΛ ΨλΙγΛ ΛΈΛ«, ΛΙΛΑΛΥΛοΛΪΛιΛ ΛΪΛΟΛΩΓΘ;
Λ»ΛΛΛΠΛοΛ±Λ«ΛόΛ»ΛαΛκΛ»,
- PPM-A, PPM-C = Witten-Bell + Katz' Back-off ΓΝ HDP
- PPM-B, PPM-D = Kneser-Ney ΛΈΤΟ ΧΛ ΨλΙγ ΓΝ ≥§ΝΊPitman-YorΛΈΤΟ ΧΛ ΨλΙγ
Λ»ΛΛΛΠΛ≥Λ»Λ«, ΑΒΫΧΛ«Ζ–Η≥≈ΣΛΥΙβά≠«ΫΛάΛΟΛΩΦξΥΓΛœΦΪΝ≥ΗάΗλΫηΆΐ/≤ΜάΦΗάΗλΫηΆΐΛΈ
ΦξΥΓΛ»Τ±ΛΗΛάΛΟΛΩ, Λ»ΛΛΛΠΖκœάΛΥΛ ΛκΛηΛΠΛ«ΛΙΓΘ
#1
"The Infinite Tree"
ΛΉΛœΓΘ
Ψ·ΛΖΆΨΆΒΛ§Λ«Λ≠ΛΩΛΈΛ«, 1ΞωΖνΛ·ΛιΛΛΝΑΛΥ
Finkel
ΛΈΛ»Λ≥ΛμΛ«Τ…ΛαΛκΛηΛΠΛΥΛ ΛΟΛΩ
"The Infinite Tree"
(ACL 2007)ΛρΤ…ΛσΛ«ΛΏΛΩΓΘ
ΛœΛΟΛ≠ΛξΗάΛΟΛΤ»σΨοΛΥΤ…ΛΏΛΥΛ·ΛΛΛΈΛ«, Α ≤ΦΛΥΦΪ §Ά―ΛΈΑ’ΧΘΛβΛ≥ΛαΛΤάΑΆΐΓΘ
ACLΛΈAccepted PaperΛ§Ϋ–ΛΩΜΰΛΥΞΩΞΛΞ»ΞκΛρΗΪΛΤΰηΞΟΛ»ΛΖΛΩΛοΛ±Λ«ΛΙΛ§,
Κ«ΫιΛΥΫώΛΛΛΤΛΣΛ·Λ», Λ≥ΛλΛœΥΆΛΈœΟΛ»ΛœΝ¥Ν≥¥ΊΖΗΛΔΛξΛόΛΜΛσΓΘ
ΞΩΞΛΞ»ΞκΛρΗΪΛκΛ», ΥΆΛΈœΟΛΈΛηΛΠΛΥΧΎΛΈΩΦΛΒΛ§ΧΒΗ¬Λ«ΛΔΛκΛΪΛΈΛηΛΠΛ Ημ≤ρΛρΛΖΛΤ
ΛΖΛόΛΛΛόΛΙΛ§, Φ¬ΛœΛ≥ΛΈΨλΙγΛΈΧΎΛœΙΫ ΗΧΎΛ ΛΈΛ«Ά≠Η¬Λ«
(ΛΫΛλΛ…Λ≥ΛμΛΪ, ΧΎΙΫ¬ΛΦΪ¬ΈΛœgivenΛάΛ»ΛΖΛΤΛΛΛκ), ΛΩΛάΧΎΛΈΞΩΞΑ
( ΗΥΓ≈ΣΛ ≤ράœΛ«Λœ, NPΛ»ΛΪVPΛ»ΛΪΩΆ¥÷Λ§ΆΩΛ®ΛΤΛΛΛκΛβΛΈ) ΛΈΦοΈύΩτΛΥΨεΗ¬Λ§Λ ΛΛ,
Λ»ΛΛΛΠœΟΓΘ
ΛόΛΚΞβΞΝΞΌΓΦΞΖΞγΞσΛœ, ΡΧΨοΛΈ ΗΥΓ≈ΣΛ ΞΩΞΑΛœΝΤΛΙΛ°ΛΩΛξ, Β’ΛΥΚΌΛΪΛΙΛ°ΛΩΛξΛΙΛκ
ΛΈΛ«, ΛΫΛλΛρΓ÷Ξ«ΓΦΞΩΛΈ ΘΜ®ά≠ΛΥ±ηΛΟΛΤΓΉΞΈΞσΞ―ΞιΞαΞ»ΞξΞΟΞ·ΞΌΞΛΞΚΛ«ΦΪΤΑ≈ΣΛΥΖηΛα
ΛΩΛΛ, Λ»ΛΛΛΠΛ≥Λ»ΓΘ
ΧΎΙΫ¬ΛΛ§PTBΛΈΛηΛΠΛΥΆΩΛ®ΛιΛλΛΤΛΛΛκΛ»ΛΙΛκΛ», Χδ¬ξΛœΛΩΛά, ΧΎΛΈ≥ΤΞΈΓΦΞ…ΛΥΛ…ΛσΛ
ΞΩΞΑ(1,2,ΓΡ,Γγ)ΛρΩΕΛκΛΪ, Λ»ΛΛΛΠœΟΛάΛ±ΛΥΛ ΛκΓΘ
ΛΩΛ»Λ®Λ–,
<- ---->
/ \/ \
* * *<--*
| | | |
She ate the cake.
Λ»ΛΛΛΠ…ςΛΥΧΎΛ§Λ«Λ≠ΛΤΛΛΛκΜΰ, …αΡΧΛœΫγΛΥΧΎΛΈ≥ΤΞΈΓΦΞ…ΛΥ, ΫγΛΥ
NN, VP, DT, NN Λ»ΛΛΛΠΞιΞΌΞκΛρΩΕΛκΛ§, Λ≥ΛΈΛ»Λ≠ΧΎΝ¥¬ΈΛΈ≥ΈΈ®Λœ,
ΞΈΓΦΞ…¥÷Λ§ΩΤΜ“ΛΥΛ Λκ≥ΈΈ®ΓΏΞΈΓΦΞ…ΛΪΛιΟ±ΗλΛ§Ϋ–ΈœΛΒΛλΛκ≥ΈΈ®Λ«,
L = p(NN|VP)p(NN|VP)p(DT|NN)ΓΏp(she|NN)p(ate|VP)p(the|DT)p(cake|NN)
ΛΈΛηΛΠΛΥΛ Λκ(Φ¬ΚίΛœΚΤΒΔ≈ΣΛΥΫώΛ±Λκ)ΓΘ
*1
ΛΛΛό, ΞιΞΌΞκΛ§Ά≠Η¬Λ«ΩΆΛ§ΆΩΛ®ΛΤΛΛΛκΨλΙγΛœΨεΛΈp(NN|VP)ΛΈΛηΛΠΛ ≥ΈΈ®ΛœΞ≥ΓΦΞ―ΞΙ
ΛΪΛιΖΉΜΜΛΙΛλΛ–ΛΛΛΛΛ§, Λ≥ΛλΛ§ΧΛΟΈΛ«, ≤ΡΜΜΧΒΗ¬ΗΡΛάΛΟΛΩΨλΙγΛœΛ…ΛΠΛΙΛκΛΪ,
Λ»ΛΛΛΠΛΈΛ§Λ≥Λ≥Λ«ΛΈΧδ¬ξΓΘΛΡΛόΛξ, ≥ΤΞΪΞΤΞ¥ΞξΛΥΦΪΝ≥ΩτΛρΩΕΛΟΛΤ,
p(1|2)p(1|2)p(3|1).. ΛΈΛηΛΠΛ ≥ΈΈ®Λ§Κ«Λβ≥ΈΛΪΛιΛΖΛΛ≥δΛξ≈ωΛΤΛρΝΣΛ÷Λ≥Λ»ΛΥ
Λ ΛκΓΘ
Λ≥ΛλΛœΆΉΛΙΛκΛΥ, ΞΩΞΑjΛ§ΞΩΞΑkΛΈΜ“ΕΓΛΥΛ Λκ≥ΈΈ® p(j|k) ΛρΙ‘ΈσΛΥΛΖΛΤ,
j
1 2 3 4 5 6 ..
+-----------------
1 |
k 2 |
3 |
: |
Λ»ΛΛΛΠ≤Ρ ―ΡΙΛΈΞΤΓΦΞ÷ΞκΛ», ΞΩΞΑkΛΪΛιΛΈΟ±ΗλΛΈΫ–Έœ≥ΈΈ®,
ΛΫΛλΛΥΫΨΛΟΛΩΞΈΓΦΞ…ΛΈΞΩΞΑΛρΒαΛαΛκœΟΛΥΛ ΛκΓΘ
ΛΛΛό, Λ≥ΛΈΙ‘ΈσΛΈ≥ΤΙ‘ p(ΓΠ|k) Λœ≥ΈΈ® §…έΛ ΛΈΛ«, Λ≥ΛλΛœDPΛΪΛιΦηΛκΛΈΛ§ΦΪΝ≥ΓΘ
ΛΩΛάΛΖ, ≥ΤΙ‘Λρ ΧΓΙΛΥDPΛΪΛιΞΒΞσΞΉΞκΛΙΛκΛ»ΆΉΝ«Λ§ΕΠΆ≠ΛΒΛλΛ ΛΛΛΈΛ«,
Ξ·ΞιΞΙΞΩjΛρΕΠΆ≠ΛΙΛκΛΩΛαΛΥΛœ, Λ≥ΛλΛρ(1Ο ≥§ΛΈ)HDPΛΥΛΙΛκ…§ΆΉΛ§ΛΔΛκΓΘ
..Λ≥ΛλΛ«άβΧάΛœΛέΛ»ΛσΛ…ΫΣΛοΛξΓΘ
œά ΗΛ«ΫώΛΛΛΤΛΔΛκ
m
jk Λ§, ΨεΛΈ p(j|k) ΛρΒαΛαΛκCRPΛΈΞΪΞΠΞσΞ»Λ«, Π¬Λ§HDPΛΈΑλ»÷≤ΦΛΈbase measure
ΛΈΞΪΞΠΞσΞ»ΓΘΛ≥ΛλΛρ¥πΛΥΛΖΛΤ, ≥ΤΟ±ΗλΛΥ NP, VP, .. ΛΈΛΪΛοΛξΛΥΛΫΛΈΩΤΜ“¥ΊΖΗΛ§
Ν¥¬ΈΛΈ≥ΈΈ®ΛρΚ«¬γΛΥΛΙΛκΛηΛΠΛ , ΦΪΝ≥ΩτΛΈΞΩΞΑ 1,2,3,.. ΛρΞΒΞσΞΉΞξΞσΞΑΛΖΛΤΛΛΛ·,
Λ»ΛΛΛΠΞβΞ«ΞκΛΥΛ Λκ, ΛΈΛάΛ»ΜΉΛΠΓΘ
ΞΩΞΛΞ»ΞκΛβΛΫΛΠΛάΛ§, œά ΗΛΈΚ«ΗεΛΥ "permit completely unsupervised learning
of dependency structure"Λ»ΫώΛΛΛΤΛΔΛκΛΈΛ«, ΑΆ¬ΗΙΫ¬ΛΧΎΛρunsupervisedΛ«≥ΊΫ§ΛΖΛΤ
ΞΩΞΑΛρΛΡΛ±ΛκœΟΛ ΛΈΛΪΛ»ΜΉΛΟΛΤΛΛΛΩΛι, ΧΎΛœΛβΛΠΆΩΛ®ΛιΛλΛΤΛΛΛΤ, Ο±ΛΥΛΫΛΈΞΩΞΑ…’Λ±
ΛρΖηΛαΛκœΟΛάΛ±ΛάΛΟΛΩΓΘΟΠΈœΓΘ
*2
Liang ΛΈ "Infinite PCFG using HDP"
(EMNLP 2007)
[link]
ΛΈ ΐΛ§ΛΚΛΟΛ»ΞλΞΌΞκΛ§ΙβΛΫΛΠΛ œΟΛ«,
Λ≥ΛΝΛιΛΈ ΐΛ§ΥήΆηACLΛΥΛ’ΛΒΛοΛΖΛΛœΟΛάΛ»ΜΉΛΠΛ§, Infinite PCFGΛœΝ¥ΈœΛ«ΛόΛ»ΛβΛ
ΤβΆΤΛρΫώΛΛΛΤΛΛΛκΛΈΛ«(PCFG-HMM, HDP-HMM, Structured Mean Field), ACLΛΈ
ΞλΞ”ΞεΓΦΞΔΛ§Άΐ≤ρΛ«Λ≠Λ ΛΪΛΟΛΩΛΈΛ«ΛœΛ ΛΛΛΪ, Λ»ΝέΝϋΓΘ
FinkelΛΈ ΐΛœ, DPΛδHDPΛΈάβΧάΛρ≈”ΟφΛ«ΡΙΓΙΛ»ΛΖΛΤΛΛΛΤ(ΛΫΛλΛρΟΦάόΛκΛ», ΨεΛΈΛηΛΠΛΥ
Ο±ΫψΛ άβΧάΛΥΛ Λκ), ΤώΛΖΛ·ΛΤΞΙΞΏΞόΞΜΞσΞΆ, ΛΈΛηΛΠΛ ΤβΆΤΛόΛ«Κ«ΗεΛΥΫώΛΛΛΤΛΔΛκΓΘ
*3
HPYLMΛΈœΟΛβΛΫΛΠΛάΛΟΛΩΛΖ,
ΛΫΛ≥ΛόΛ«Μ“ΕΓΛΥΫώΛ·ΛηΛΠΛΥΫώΛΪΛ ΛΛΛ»ΡΧΛιΛ ΛΛΛ ΛσΛΤ, ACLΛΟΛΤΛΛΛΟΛΩΛΛ..
Λ»ΜΉΛΟΛΤΛΖΛόΛΟΛΩΓΘ
*1: Λ≥ΛλΛœ, Μ“ΕΓΛΈ≥ΈΈ®ΛρΤ»Έ©ΛΥΖΉΜΜΛΙΛκ"independent child"ΛΈΨλΙγΓΘ
œά ΗΛ«Λœ, Μ“ΕΓΛρΫγ»÷ΛΥάΗά°ΛΙΛκ "Markov child" ΛΈ ΐΛ§ά≠«ΫΛ§ΛηΛΪΛΟΛΩ
Λ»ΫώΛΪΛλΛΤΛΛΛκΓΘ
*2: Λ»ΛœΛΛΛΠΛβΛΈΛΈ, Λ≥ΛλΛ«ΑΆ¬ΗΙΫ¬ΛΧΎΛ§ΆΩΛ®ΛιΛλΛλΛ–, ΛΫΛλΛΥ¥ΑΝ¥ΛΥΦΪΤΑ≈ΣΛΥ
ΞΩΞΑΛρΩΕΛλΛκΛ≥Λ»Λ§Φ®ΛΒΛλΛΩΛοΛ±Λ«,
Φ¬Ά―≈ΣΛ Α’ΧΘΛœΫΫ §ΛΥΛΔΛκΛ»ΜΉΛΠΓΘ
ΦΪΧάΛ ±ΰΆ―Λœ, …αΡΧΛΥ dependency parsing ΛρΛΖΛΩΗε, Λ≥ΛΈ ΐΥΓΛ«ΑΆ¬ΗΙΫ¬ΛΛΥΞΩΞΑΛρ
…’ΆΩΛΙΛκΛ»ΛΛΛΠΛ≥Λ»ΛάΛ§, ΥήΆηΛœΛΫΛΈΤσΛΡΛρΤ±ΜΰΛΥΛδΛκΛΈΛ§ΆΐΝέ≈ΣΛ«, Ε≤ΛιΛ·
ΛΔΛκΡχ≈ΌΛœΛδΛΟΛΤΛΛΛκΛΈΛ«ΛœΛ ΛΛΛΪΛ , Λ»ΓΘ
*3: DP, HDP, HPYΛΈΖΉΜΜΛρΝ¥…τΞ’Ξ©ΞμΓΦΛΖΛΩΥΆΛ§Τ…ΛσΛ«Λβ, ΫώΛ≠ ΐΛ§ΛοΛΪΛξΛΥΛ·Λ·ΛΤ
≤Ω≈ΌΛβΤ…ΛΏ ÷ΛΒΛ ΛΛΛ»ΛοΛΪΛιΛ ΛΪΛΟΛΩœά ΗΛ«, Υή≈ωΛΥΛ≥ΛλΛ§ΫΦ §Άΐ≤ρΛΒΛλΛΤ
ΞλΞ”ΞεΓΦΛρΡΧΛΟΛΩΛΈΛΪ, ΛΝΛγΛΟΛ»ΒΩΧδΓΘ
Λ≥ΛΈΤβΆΤΛάΛ»Mark JohnsonΛΔΛΩΛξΛΥΞλΞ”ΞεΓΦΛ§Ι‘ΛΟΛΤΛΛΛλΛ–, ΑλΩΆΛœΆΐ≤ρΛ«Λ≠ΛΫΛΠ
Λ«ΛΙΛ§..ΓΘ
#1
Ϋώ≈Ι
Κ«Εα(ΛάΛΛΛΩΛΛ1«·»ΨΛ·ΛιΛΛΝΑ)ΛΥΞΣΓΦΞΉΞσΛΖΛΩ, Ης¬φΛΈ
Λ±ΛΛΛœΛσΛ ΞφΓΦΞΩΞΠΞσ
ΛΥΤΰΛΟΛΤΛΛΛκΫώ≈Ι, ACADEMIA Λ±ΛΛΛœΛσΛ ≈ΙΛΥΛ≥ΛΈ¥÷Λ»Λ≥ΛΈΤϋ, ΫιΛαΛΤΤΰΛΟΛΤΛΏΛΩΓΘ
Ϋ–ΆηΛΤΛΙΛΑΛΪΛι¬ΗΚΏΛœΟΈΛΟΛΤΛΛΛΩΛ§, Γ÷ACADEMIA? Λ…ΛΠΛΜΧΨΝΑΛάΛ±ΛΗΛψΛ ΛΛΛΈ?
ΛδΛόΛΕΛ≠Β°Μ“ΛΈΧΓ≤ηΛΗΛψΛ ΛΛΛσΛάΛΪΛιΛΒΓΡΓΉΛ»ΜΉΛΟΛΤΛΛΛΩΛΈΛάΛ§..
..ΛΙΛΛΛόΛΜΛσΛ ΛαΛΤΛόΛΖΛΩΓΘ
νΝΛΥΛœΒ©Λ , ΑΑ≤ΑΫώ≈ΙΛΈΛηΛΠΛ ≈‘≤ώΛΈάλΧγ≈ΙΛ ΛΏΛΈ… ¬ΖΛ®Λ«ΕΟΛΛΛΩΓΘ
…αΡΧΛΈΟœ ΐΛΈΥή≤ΑΛΥΛœΛόΛΚΟ÷ΛΛΛΤΛΛΛ ΛΛ, ΛΏΛΙΛΚΫώΥΦΛΈΥή(Ν¥…τΛ«ΛœΛ ΛΛΛ«ΛΙΛ§)Λδ,
«ρΩεΦ“Ξ·ΞΜΞΗΞε ΗΗΥΛΈΛηΛΠΛ ΛβΛΈΛόΛ«Ο÷ΛΛΛΤΛΔΛκΓΘ
Ρ¥ΛΌΛκΛ»,
Λ·ΛόΛΕΛοΫώ≈Ι
ΛΈ≈Η≥ΪΛΈΛΠΛΝ, Ν¥ΙώΛΥΩτΗΡΫξΛΔΛκACADEMIA≈ΙΛΈΑλΛΡΛιΛΖΛΛΓΘ
…αΡΧΛΈΥήΛœΛβΛΝΛμΛσ, ΗΖίΫώ, ≤ ≥ΊΫώΛ»Λβ»σΨοΛΥΫΦΦ¬ΛΖΛΤΛΛΛκΓΘ
ΈψΛ®Λ–
Γ÷ΦΪΝ≥≥ΠΛΥΛΣΛ±ΛκΚΗΛ»±ΠΓΉ
Λ»ΛΪΛ§…αΡΧΛΥΟ÷ΛΛΛΤΛΔΛκΛοΛ±Λ«ΛΙΛ§,
ΤΟΛΥΜ“ΕΓΛΥΛ»ΛΟΛΤΛœ, ≈‘≤ώΛΥΫ–ΛΤ¬γΖΩΫώ≈ΙΛΥΙ‘ΛΟΛΩΛξΛΙΛκΛΈΛœΧΒΆΐΛ ΛΈΛ«, Λ≥ΛΠΛΛΛΠ
ΥήΛ§…αΡΧΛΥΕαΛ·ΛΈΥή≤ΑΛΥΟ÷ΛΛΛΤΛΔΛκΛ»ΛΛΛΠΛΈΛœΝ«ά≤ΛιΛΖΛΛΛ ΛΔ, Λ»ΜΉΛΟΛΤΛΖΛόΛΟΛΩΓΘ
ΤΟΛΥΜ“ΕΓΛΈΚΔΛœ, Φ¬ΚίΛΥΛΛΛΛΥήΛ§ ¬ΛσΛ«ΛΛΛκΨλΫξ(Ϋώ≈ΙΛδΩόΫώ¥έ)ΛΥΙ‘ΛΟΛΤΈ…ΛΛΛ»
ΜΉΛΠΥήΛρΝΣΛσΛ«Τ…Λύ, Λ»ΛΛΛΠΛΈΛœΛ»ΛΤΛβ¬γΜωΛάΛ»ΜΉΛΠΓΘ
ΛΩΛά, ΛΛΛ·ΛιΗς¬φΛ§ΗΠΒφΫξΛ§¬ΩΛ·, ΫΜΧ±ΛΈΞλΞΌΞκΛ§ΙβΛΛ(ΛιΛΖΛΛ)
*1
Λ»ΛœΗάΛΟΛΤΛβ, Υή≈ωΛΥΛ≥ΛλΛ«ΚΈΜΜΛ§Λ»ΛλΛΤΛδΛΟΛΤΛΛΛ±ΛκΛΈΛΪΛ ΛΔ.. Λ»Ψ·ΛΖ
Ω¥«έΛΖΛΤΛΖΛόΛΟΛΩΓΘ
*1: œΟΛΥΛηΛκΛ», Ης¬φΛΈάΚ≤ΎάΨΟφ≥ΊΙΜΛœΧ·ΛΥΞλΞΌΞκΛ§ΙβΛΪΛΟΛΩΛξΛΙΛκΛιΛΖΛΛΓΘ
#1
pdfnup
UnixΛΈTipsΓΘ
Λ≥ΛλΛόΛ«, PDFΛΈΞΙΞιΞΛΞ…≈υΛρ4up,ΈΨΧΧΛ«ΑθΚΰΛΙΛκΛΈΛΥ, UnixΛΈAdobe ReaderΛΪΛιΛœ
ΛΫΛΠΛΛΛΠΜΊΡξΛ§Λ«Λ≠Λ ΛΛΛΈΛ«, ΛΚΛΟΛ»WindowsΛΈΞΈΓΦΞ»ΛρΒ·ΤΑΛΖΛΤ, ΛΫΛΝΛιΛΪΛι
ΑθΚΰΛΖΛΤΛΛΛΩΛΈΛ«ΛΙΛ§, PDFLaTeX¥ΊΖΗΛΈΞΖΞßΞκΞΙΞ·ΞξΞΉΞ»ΫΗ
PDFjam
ΛΥ¥όΛόΛλΛκ pdfnup ΛρΜ»ΛΠΛ»
% pdfnup --nup 2x2 hoge.pdf
Λ«PDFΛρ4upΛΥΛ«Λ≠ΛΤ, …αΡΧΛΥΈΨΧΧΑθΚΰΛ«Λ≠ΛκΛΈΛρΟΈΛξΛόΛΖΛΩΓΘΞ÷ΞιΞήΓΦΓΘ
ΑθΚΰΛΖΛΤΛΏΛόΛΖΛΩΛ§, WindowsΛΪΛιΛ»¬ΫΩßΛ ΛΛΖκ≤ΧΛ§ΤάΛιΛλΛΤΛΛΛόΛΙ(UnixΛΪΛιΛΈ ΐΛ§
Φψ¥≥εΚΈοΛάΛΟΛΩ)ΓΘ
Τβ…τΛ« pdflatex ΛρΗΤΛσΛ«ΛΛΛκΧœΆΆΛ ΛΈΛ«, ΛΫΛλΛ§ΤΰΛΟΛΤΛΛΛ ΛΛΛ»Μ»Λ®Λ ΛΛΛΪΛβ
ΛΖΛλΛόΛΜΛσΛ§, ΜδΛΈΫξΛ«ΛœΤΟΛΥ≤ΩΛβΛΖΛ Λ·ΛΤΛβΤΰΛΟΛΤΛΛΛόΛΖΛΩ(tetexΛΥ¥όΛόΛλΛΤΛΛΛκ
ΛΈΛΪΛβ)ΓΘ
4 days displayed.
ΞΩΞΛΞ»ΞκΑλΆς
|  |