上で書いた「ある値でスライスした密度から一様にサンプリングする」ということは 実際には自明ではないので, もともとのスライスサンプリングでは, "stepping-out" という方法を用いて, 今パラメータのいる場所から幅wの窓を作り, それを密度の外に はみ出すまで広げる, という方法でサンプリングを行います。 これは実装が若干やっかいで, 局所的な移動しかできない, という特徴があります。
もし, パラメータの範囲が [st,ed] の範囲と決まっていればスライスサンプリングは簡単で,
- r ~ [st,ed] を一様分布に従ってサンプリングする
- その場所での確率密度 likelihood(r) がスライスより高ければ終了
- そうでなければ, もとのパラメータを含むように st または ed を r に書き換えて, 探索範囲を右側または左側に減少
- 1に戻る.
ただしこれはパラメータの範囲が [st,ed] で有界な場合で, そうでない場合は使えません。参考にしたコードが, この範囲を手で [0,25] のように書いてあったのですが, それには若干疑問があったので少し考えてみたところ, 実は常に [0,1] の範囲からの スライスサンプリングとして実現できることに気づきました。 後で書くように, この辺の話の専門家であるエジンバラの Iain Murray にメールして 聞いてみたところ, 関連のある話はあるが, そのものはまだ誰も特に言っていない ようです。
基本的なアイデアは, たとえばパラメータが正の実数全て(R+)を範囲として取る場合,
(0,1)->R+への対応付けを考えて, パラメータを実数xではなく, (0,1) の範囲の数 p として表すことです。
たとえば, p∈(0,1)について x = p / (1-p) ととれば, このxは正の実数上をすべて動きます。
逆にxが決まれば, 対応する p は p = x / (1+x) として求まります。
そうすれば (0,1) の範囲の一様分布からサンプリングすれば良いじゃん!
というわけですが, ナイーブにそれをやっても動かない, ということに試してみてから気付きました。理由は簡単で,
∫0∞f(x)dx からサンプリングしているので, 上の変換のヤコビアンが必要, ということです。
上の変換の場合, 計算すると dx/dp = 1/(1-p)^2 なのがわかるので,
dx = 1/(1-p)^2 dp と密度を変換してやれば大丈夫です。
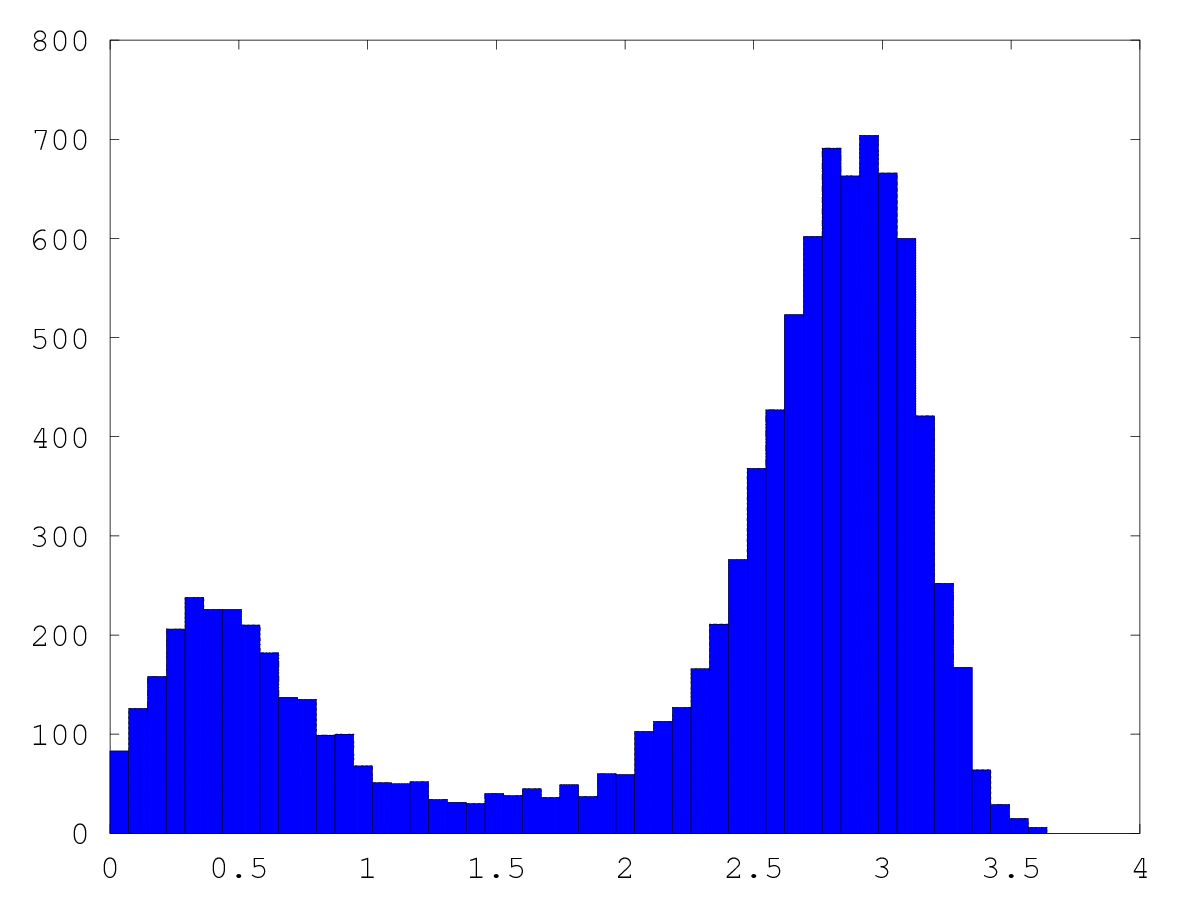
この方法で, p(x) ∝ exp(-x(x-1)(x-2)(x-3.4)) という密度からサンプリングした
ものが一番上の図で, ほぼ完全にもとの確率密度を再現していることがわかります。
ポイントは, 内部的には (0,1) の範囲でサンプリングしている, ということです。
パラメータが実数の場合は, (0,1)に値をとるシグモイド関数 y = 1/(1+exp(-x)) の逆関数を考えると, x = -log(1/p - 1) ととればよいことがわかります。 x = p/(1-p) の場合と合わせて, xとpの対応関係をグラフにしたものがこちら。
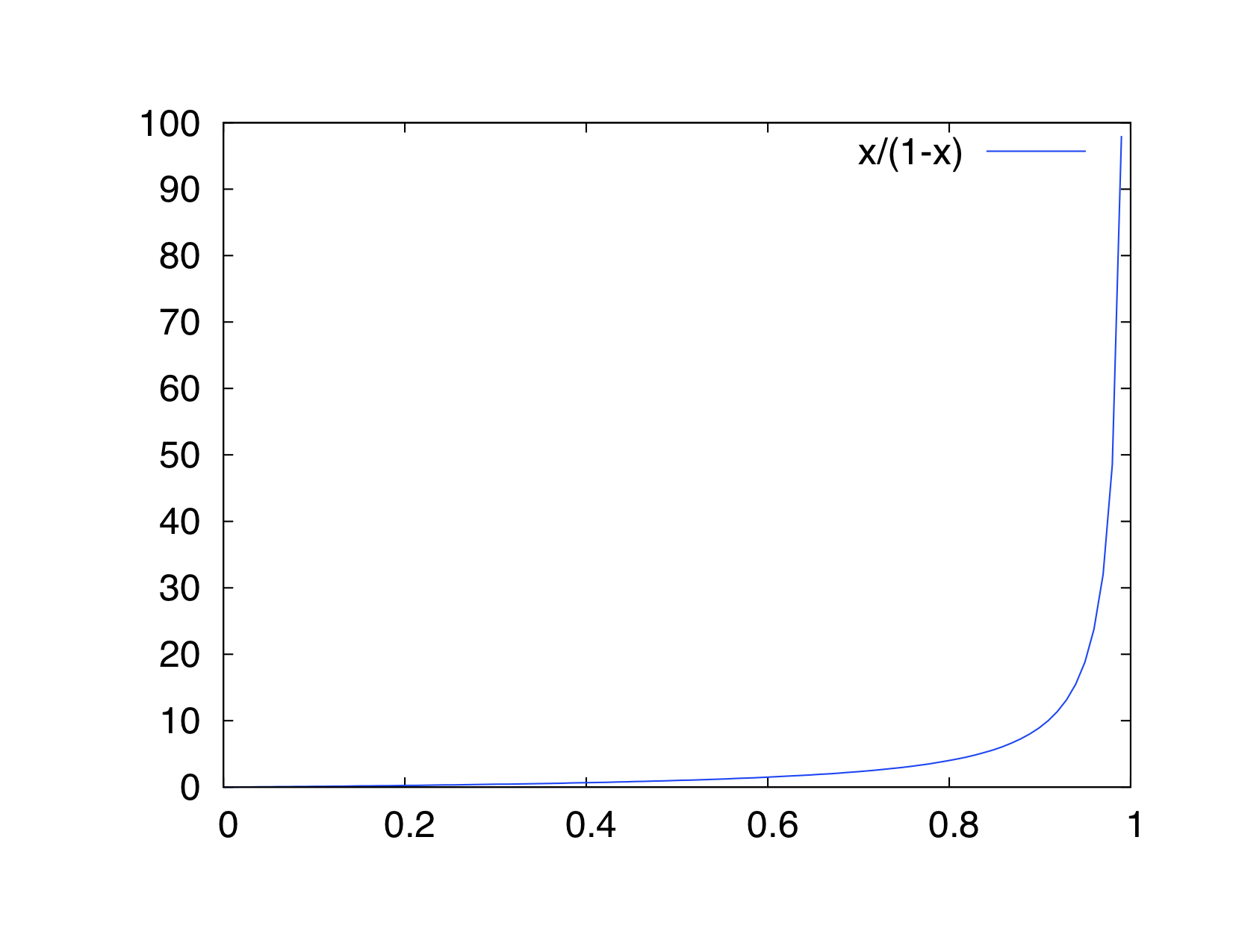 | 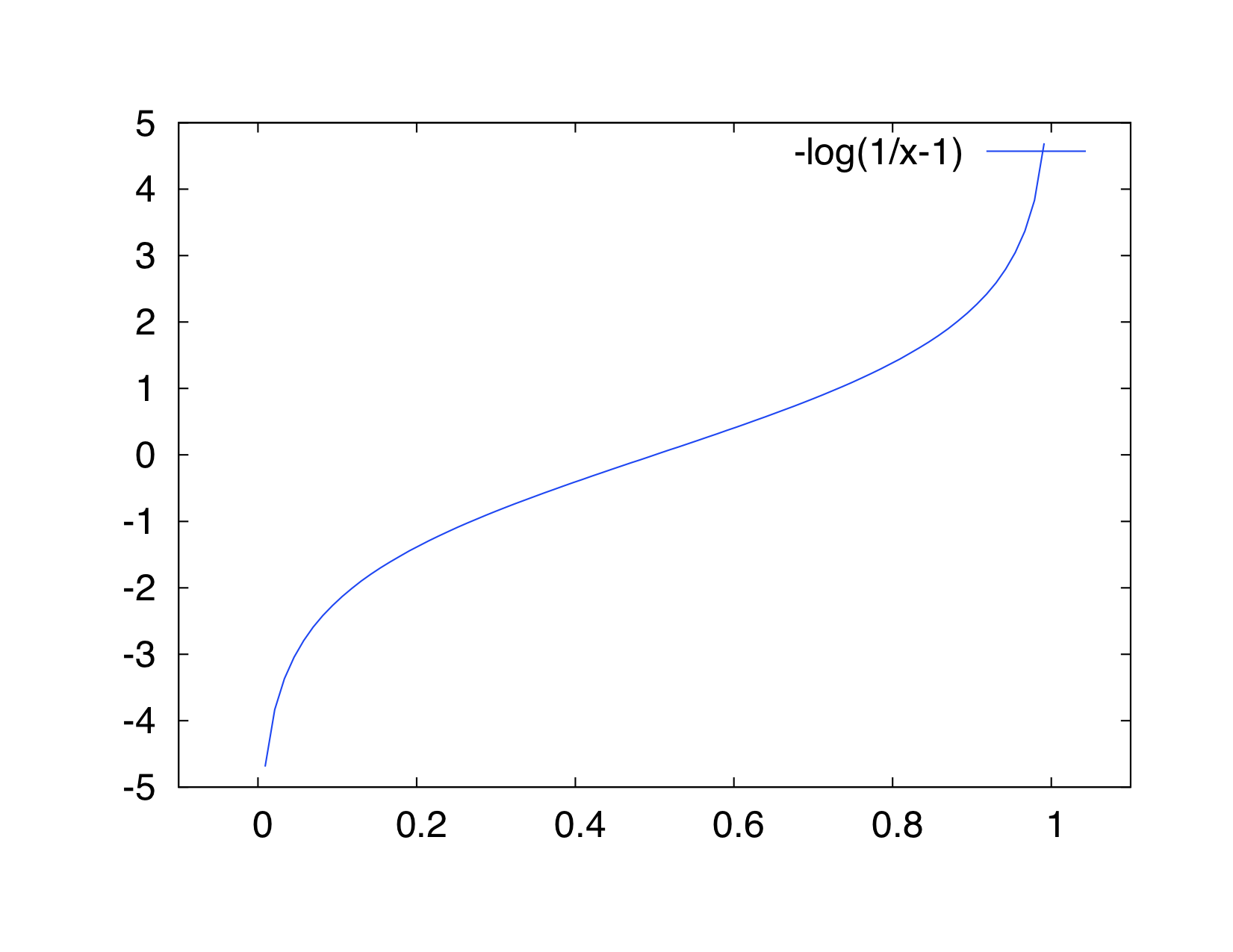 |
| x = p/(1-p) | x = -log(1/p - 1) |
こうしてimplicitに(0,1)からサンプリングしたのが下の二つのグラフで, p(x) ∝ exp(-(x-1000)^2) からのサンプルですが, 見事に x ~ 1000 の周りにサンプル が集中して, 確率密度を発見していることがわかります。 実際には, x = 1 / (1+exp(-p)) だとカーブが急峻すぎて, 大きなxに対応するpが 取れなくなってしまうようなので, x = 1 / (1+exp(-ap)) として a = 100 くらいに すると, -1000 < x < 1000 程度のxについてはpと対応がつき, サンプリングが可能 なようです。
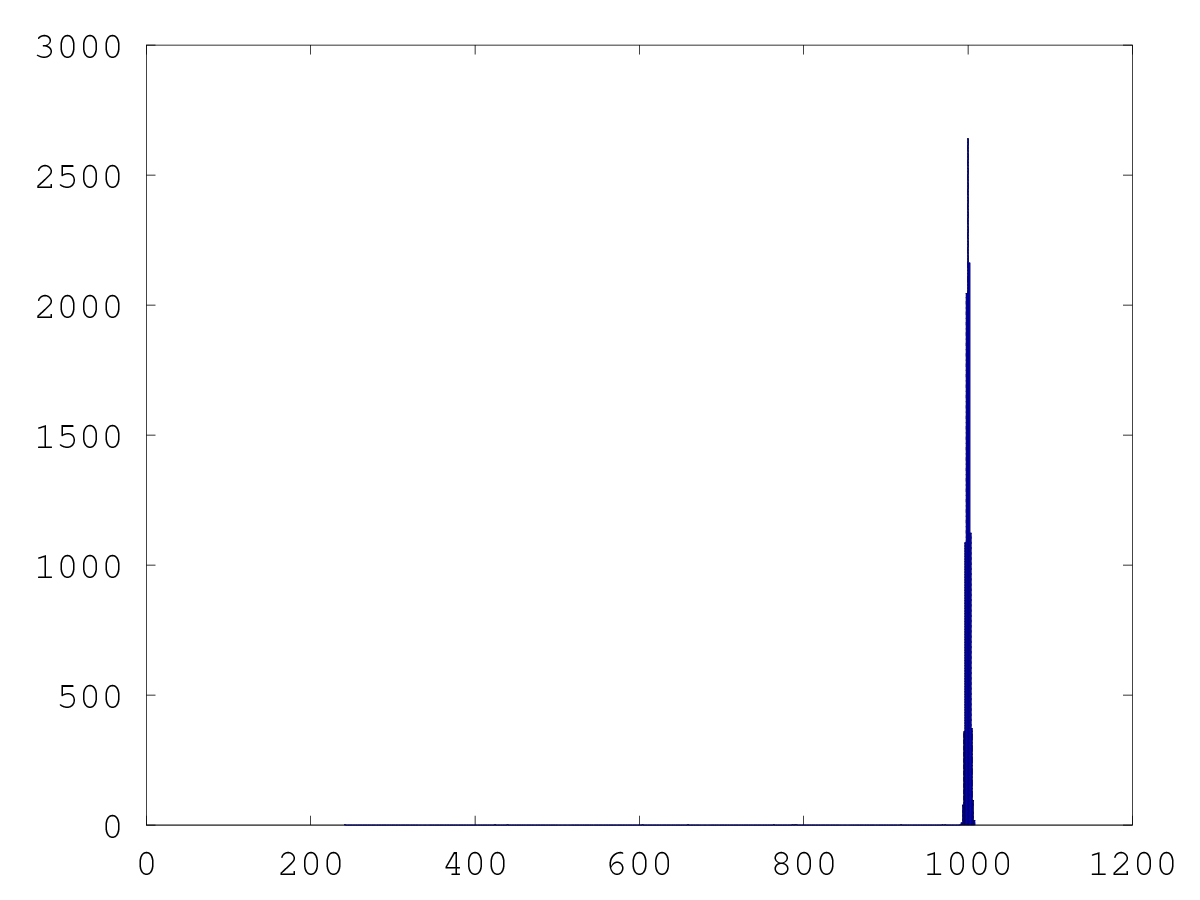 | 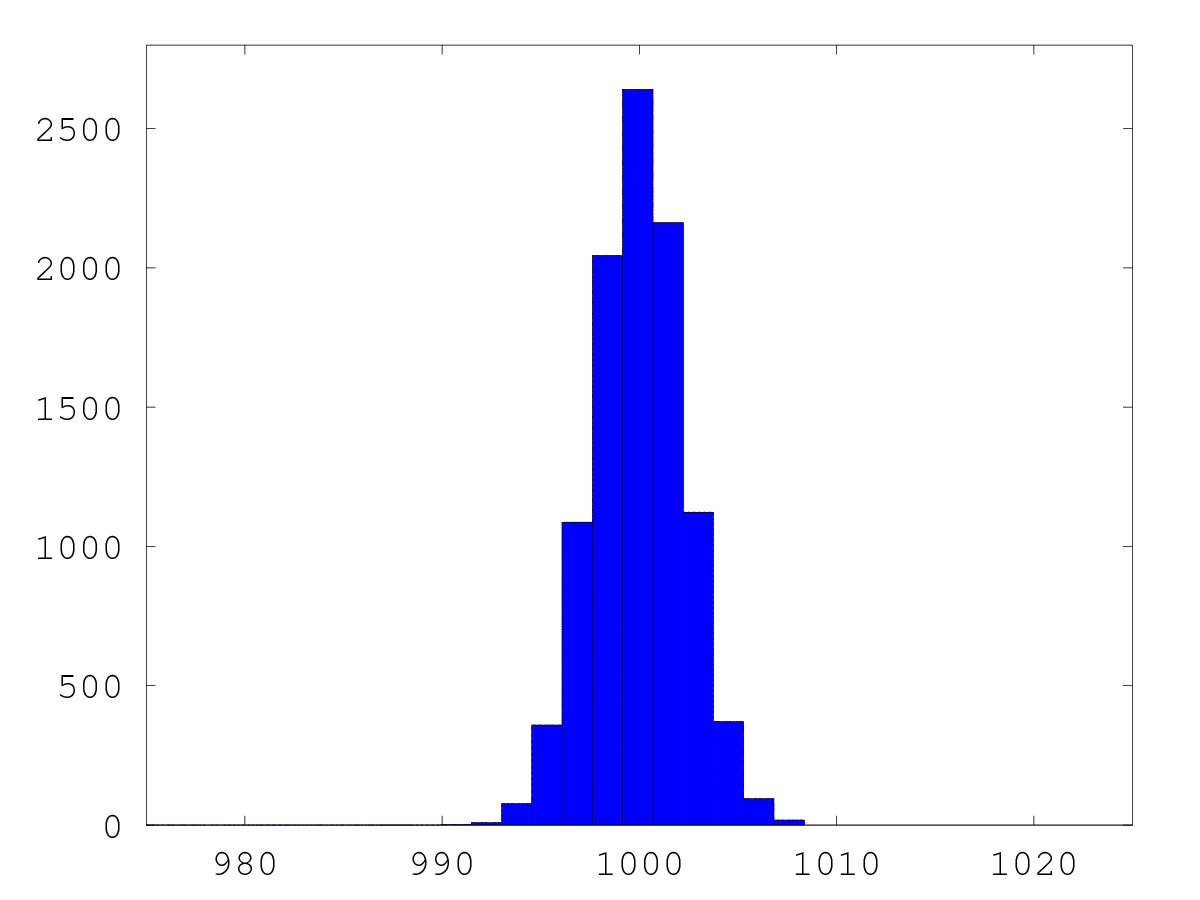 |
| p(x)∝exp(-(x-1000)^2/10) | 同左, 拡大図 |
実際に, 下のようなコードで容易に実数全体からスライスサンプリングを行うことができます。
#include "slice.h"
double
f (double x, void *arg)
{
return - x * (x - 1) * (x - 2) * (x - 3.4);
}
{
double x = 1;
for (i = 0; i < N; i++)
{
x = slice_sample (x, f, NULL);
printf("%.4lf\n", x);
}
}
C++のコードを下に置いておきますので, ご興味のある方はお使い下さい。
この話は考えてみると trivial かも知れませんが, 僕は聞いたことがないので,
どこかにノートでまとめてみると良いのかもしれません。
Iain Murrayによると, 関連した話は Skilling の話にあるそうで, 実際にMacKayの
ITILAに二進法によるスライスサンプリングの実装の話が書いてあるのですが,
そちらは unit interval を前提としたものではなく, ヤコビアンの計算もしていない
ようです。ので, 上の方法は一般性がある方法なのではないか, と思っています。