離散分布の一番基本的な分布はディリクレ分布なので, 最も素直には, これにはαをスカラーとして
θt 〜 Dir(αθt-1)とすればよいように思えます。 実際, NTT岩田君の2009年のIJCAIの論文 "Topic Tracking Model for Analyzing Consumer Behavior" でも基本的にこの方法が使われています。(ただしαが時変なので, 下の議論とは 正確には異なっています。後述)
これは一見よさそうに思えるのですが, 少し考えていて, 実はこれは時系列モデル
としては適切でないことに気付きました。
いま, 問題を最も簡単にして, 二項分布の確率
ptの時系列を考えてみます。これは上の二次元版なので,
pt 〜 Be(αpt-1,α(1-pt-1))になります(Be()はベータ分布)。 ベータ分布 Be(a,b) からの乱数は, スケール係数1 *1 のガンマ分布からの乱数 γ1〜Ga(a,1),γ2〜Ga(b,1)を生成して p = γ1/(γ1+γ2)とすればよいので, 上記の時系列モデルでは Ga(αpt-1,1)のような乱数を引くことになります。
ここでGa(a,1)はaが小さい値のとき, 0方向にきわめて偏った分布なので, pがすでに0に近い値のとき, 次の時刻の確率の値が今より大きくなる確率は pが小さいほど, どんどん小さくなっていきます。つまり, pが小さくなる方向に バイアスがかかることになります。
ということで, 実際にMATLABでプログラムを書いて試してみました。
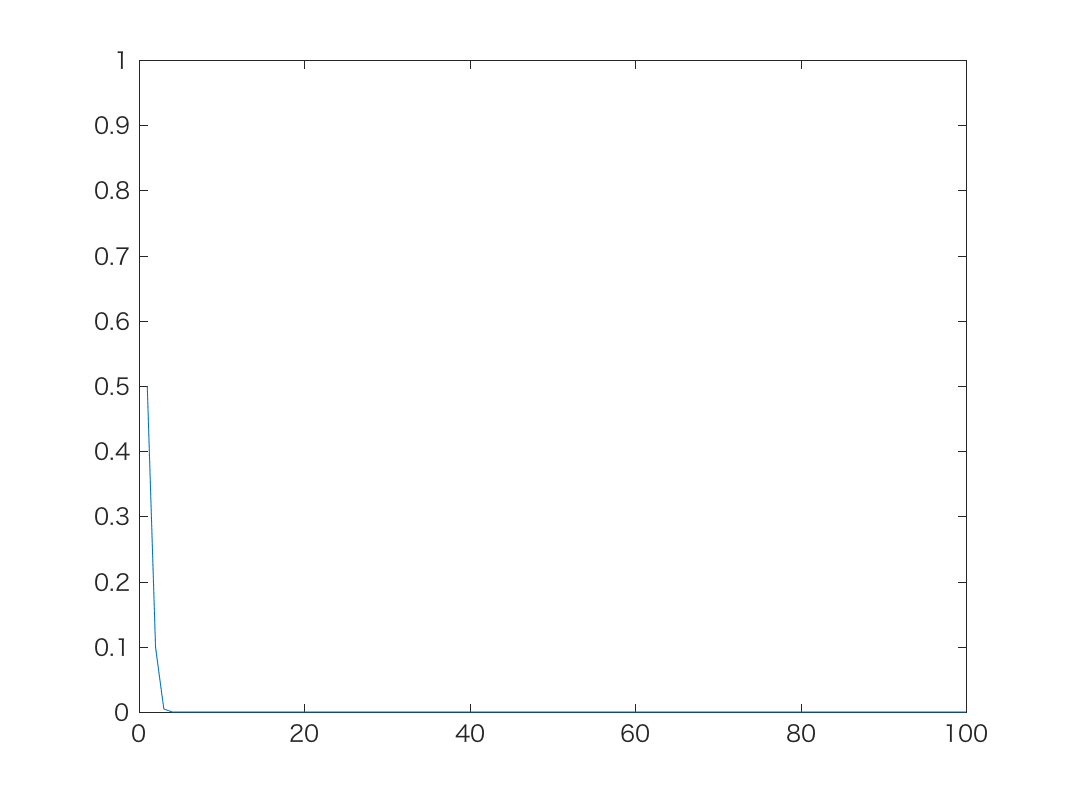
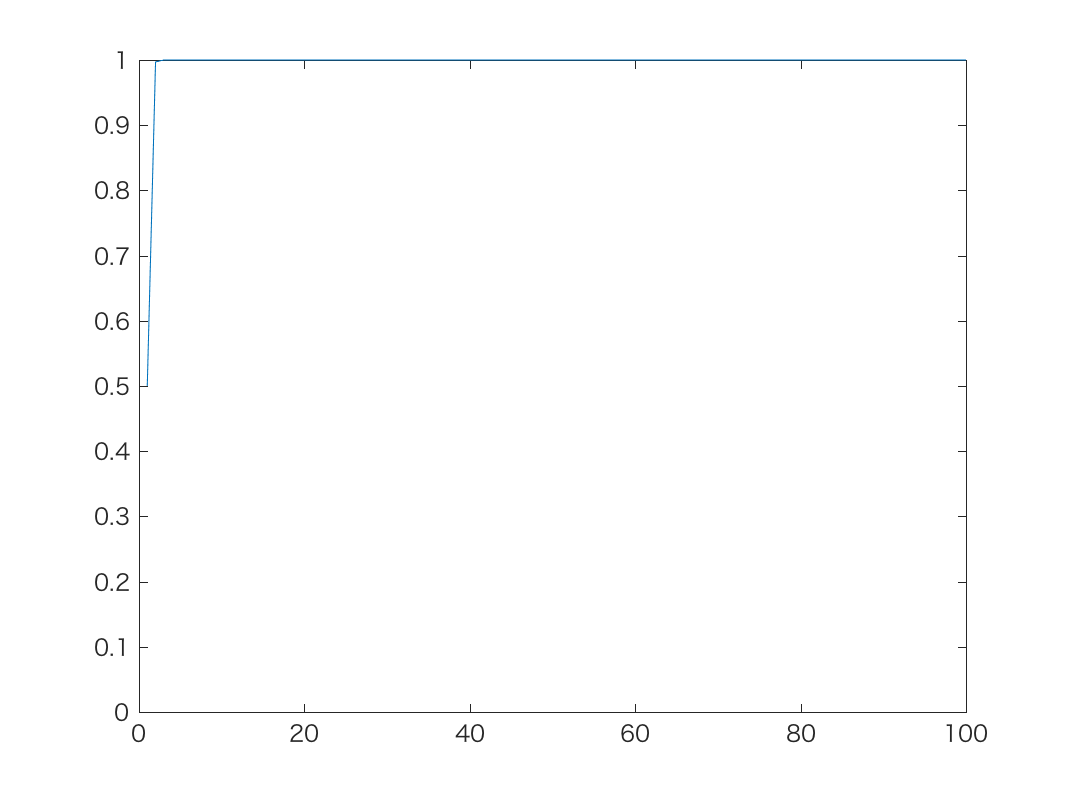
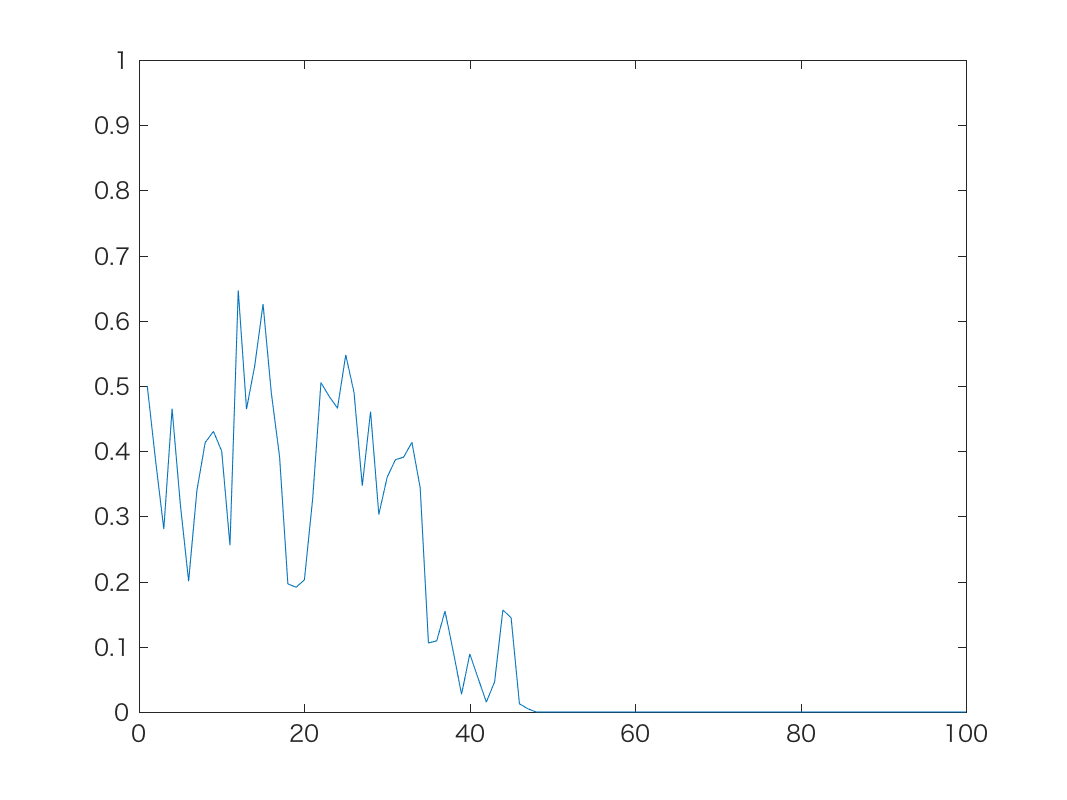
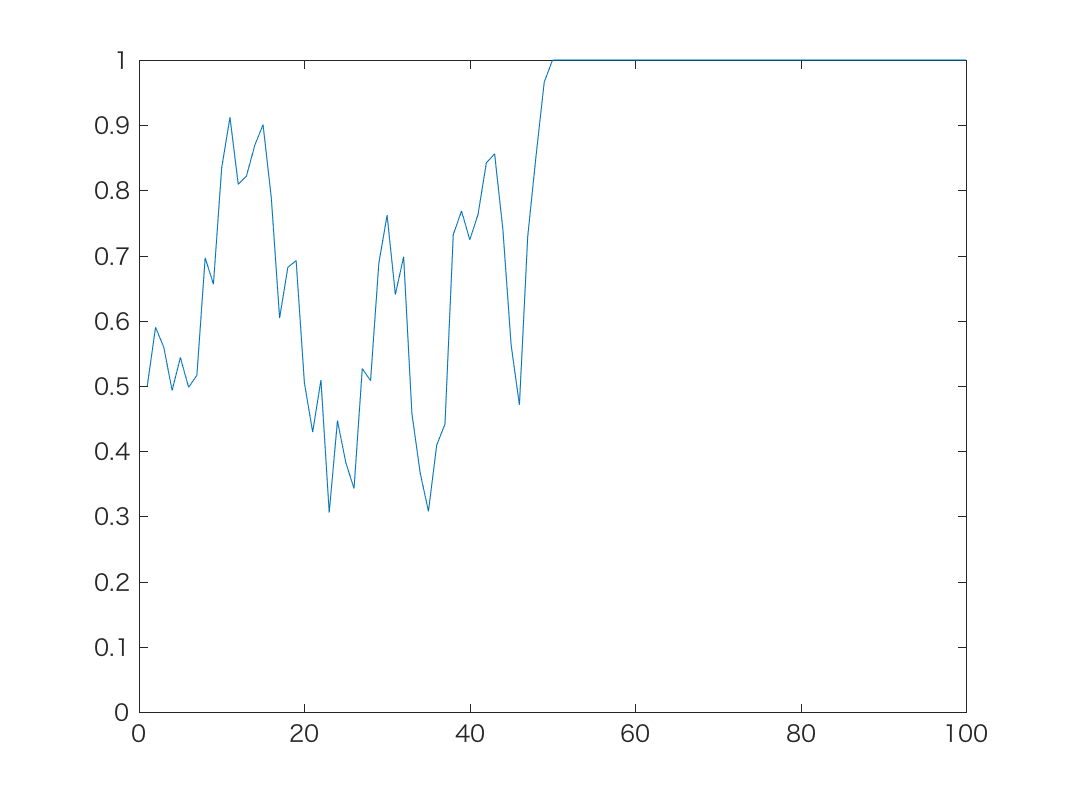
初期値がp=0.5のとき, 上記の時系列モデルで, α=1,10,100のときの結果が以下です。
α=1のとき
 |  |
 |  |
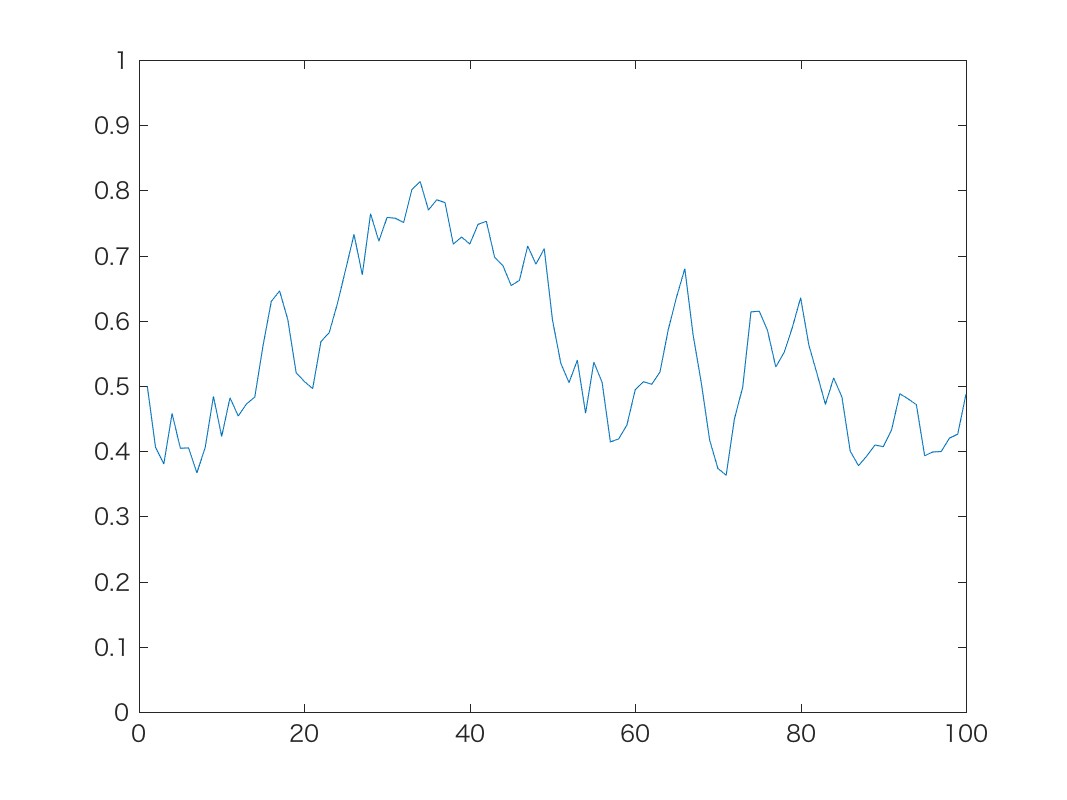 | 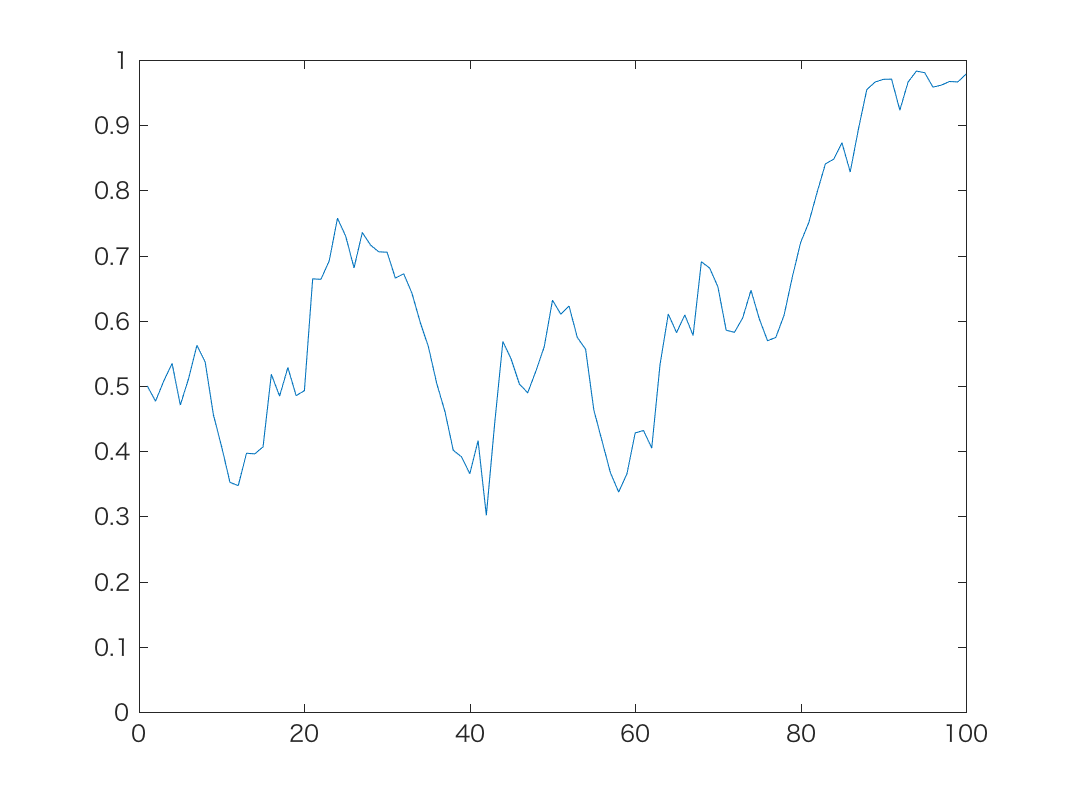 |
α=1やα=10では, 予想通り確率が最終的に0または1に吸い込まれ, 戻って これなくなることがわかります。 α=100では吸い込まれることは少ないですが, 逆にスケールが非常に大きい(=中間の 確率密度がきわめて高い)確率分布を仮定していることになるので, 確率が0や1に寄る ことができず, ほとんど0.5前後の値だけをふらふらすることになります。
というわけで, 多項分布の時系列には多項分布をそのままディリクレ分布で考える
のは不適切で, 他の分布, たとえばガウス分布をロジスティック変換したもの
(ロジスティック正規分布)のようなものを考えた方がいいように思えます。
ちなみに上の岩田君の論文では, αは固定ではなく, 時刻t毎に推定するとしている
ので, この問題は回避されていると思います。
実際にロジスティック分布, つまりガウス分布の通常のランダムウォークを
ロジスティック変換した時系列は以下のようになります。
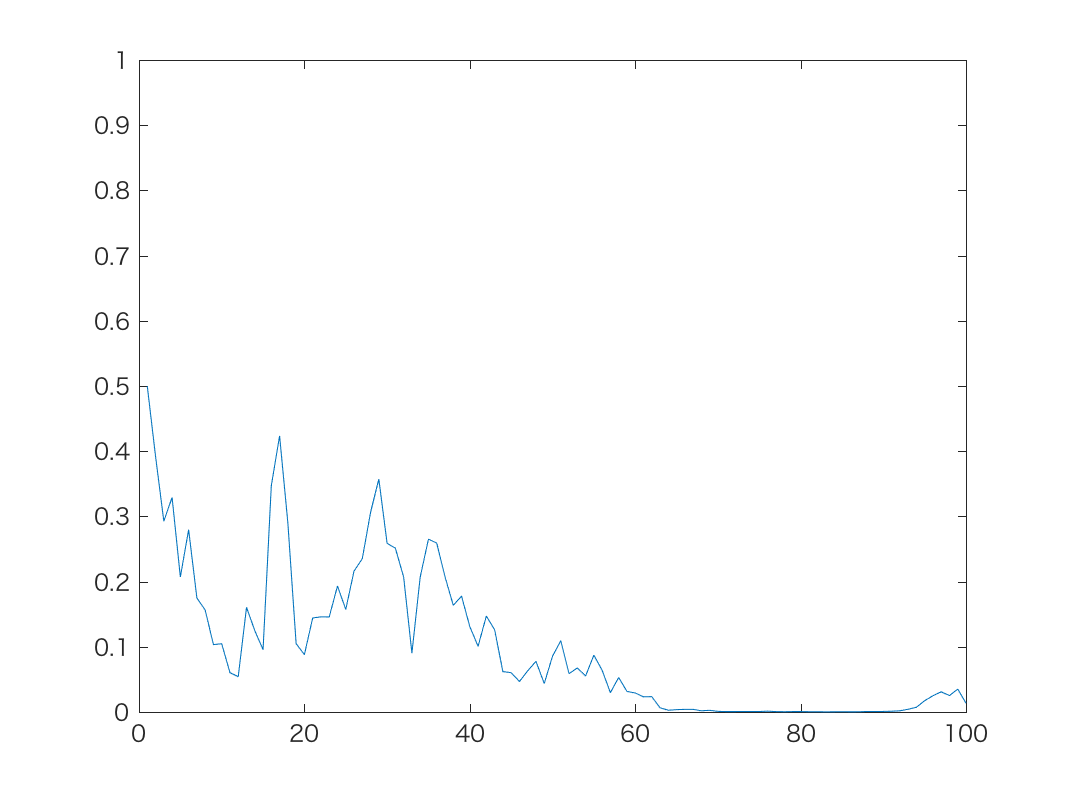 | 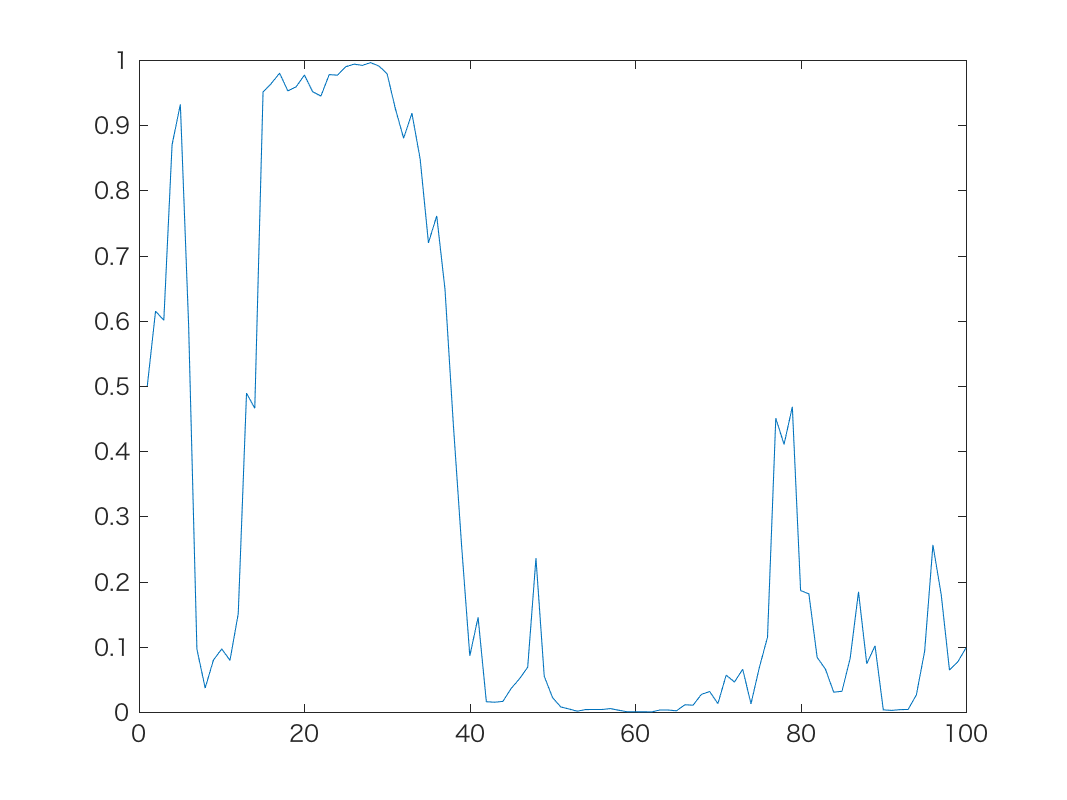 | 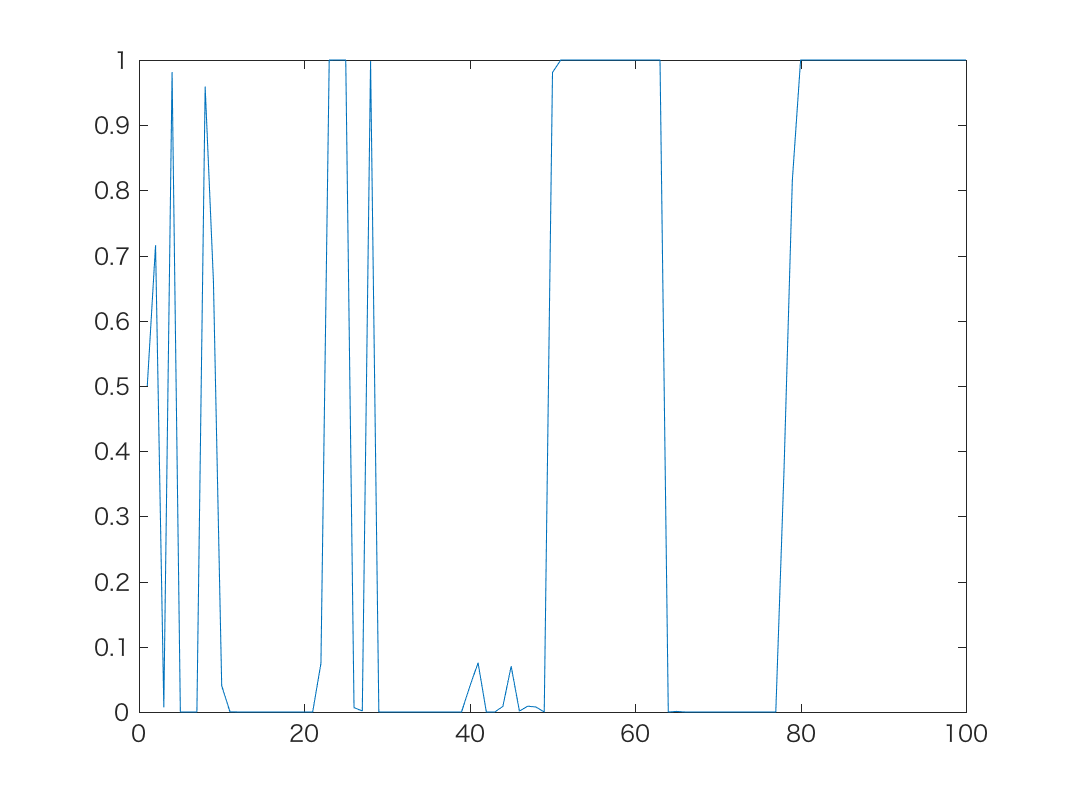 |
| α=0.5のとき | α=1のとき | α=10のとき |
他の可能性として, そもそもディリクレ分布(ディリクレ過程)は上の作り方から わかるように, 正規化ガンマ分布(ガンマ過程)なので, ガンマ分布のスケールパラメータを er倍にして動かすという方法があると思います (rは正規乱数)。 単純にガウス過程をロジスティック変換するという方向(対数ガウスCox過程)もあります。 ただいずれにしても結局正規分布やそれに似たものが入ってくるので, 時系列モデルを考える際には連続分布としてのガウス分布は避けられないのでは ないか, という気がします。 *2 そういう意味で, トピック分布の時系列にロジスティック正規分布を考える Dynamic Topic Model は(推定が変分ベイズによる近似で非常に難しいという点を除けば), 妥当なことをしているのではないかと改めて思いました。