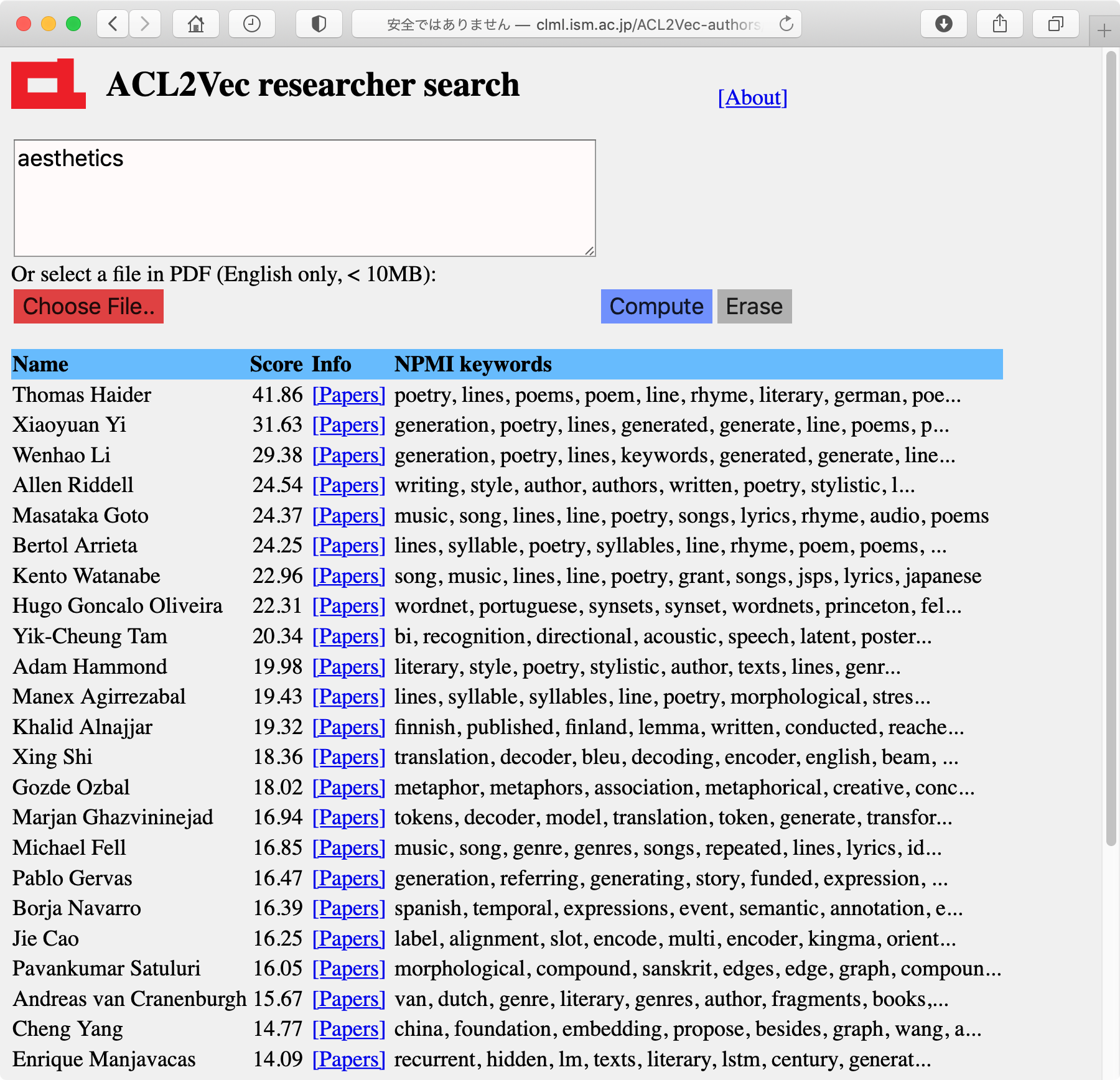
この数恕を橙磨して, Researcher2Vecにもあるように, 称甫垫荚の≈甫垫荚ベクトル∽を纷换することで, キ〖ワ〖ドから甫垫荚を浮瑚できる"ACL2Vec-authors"をさらに给倡しました。 ≈Score∽とは, 浮瑚キ〖ワ〖ドから纷换した簿鳞弄な矢今ベクトルと甫垫荚ベクトルのコサイン调违のことです。(クリックで橙络)
 | 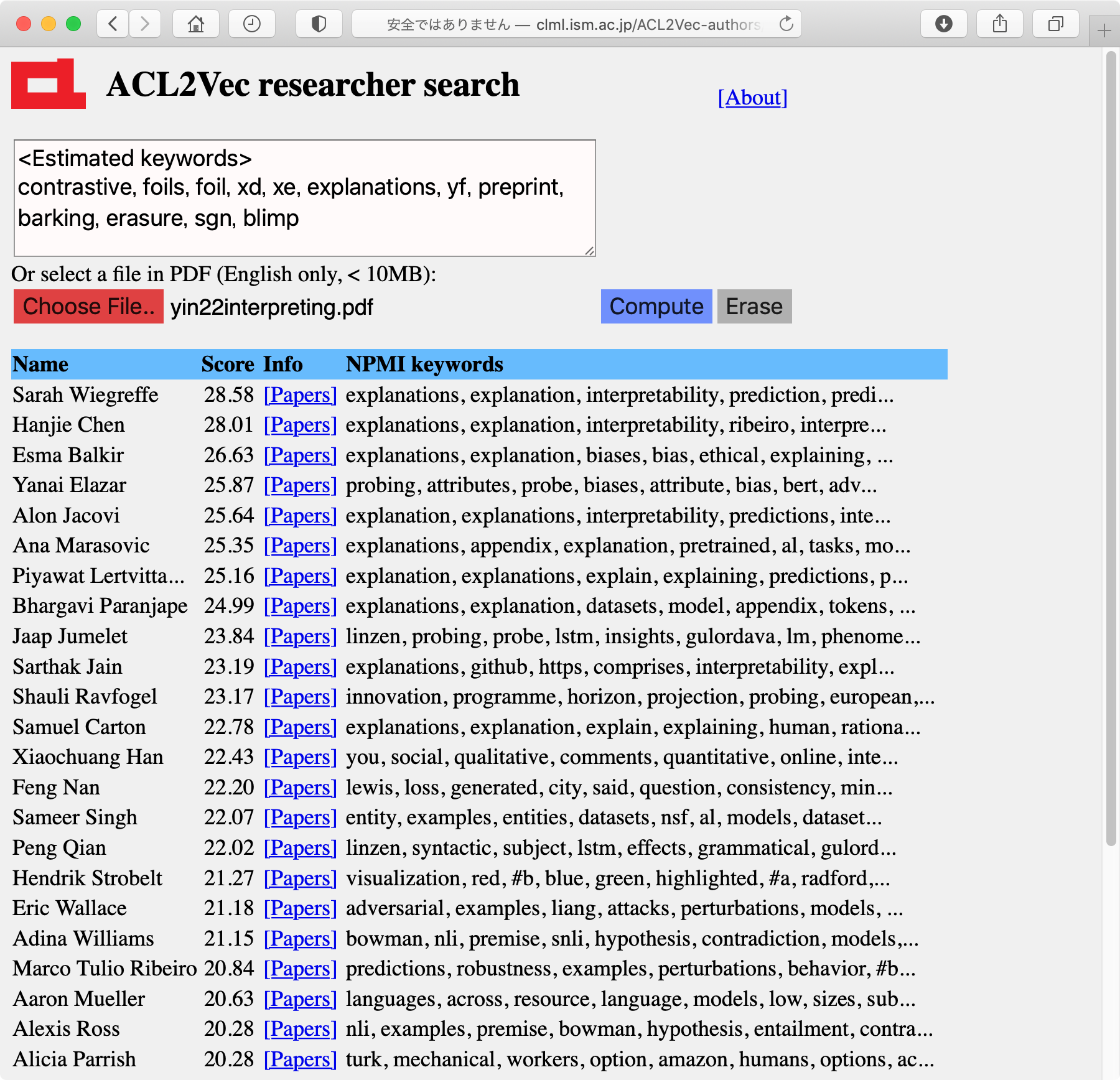 |
これは傅」は讳がTACLのEditorとして汉粕荚を斧烧けるのに, 部か极瓢步が涩妥だと炊じて倡券したものなので, キ〖ワ〖ドを掐れるだけでなく, 侠矢のPDFを回年すると, 柒婶でそれをアップロ〖ドしてテキストに木して豺老し, その琵纷翁から呵も夺い甫垫荚を山绩するシステムも崔めました。
惧淡のインタ〖フェ〖スは办斧词帽に斧えますが,
HTMLの<input type="file">をそのまま蝗うと, submit稿に回年したファイル叹が久えてしまいます。
このため, 极涟で侍に乐いボタンの<input type="button">を脱罢し, それをクリックするとCSSで润山绩にした斧えない
<input type="file"> が弹瓢され, その觉轮が恃构されるとファイル矢机误が今き垂わるようにする, というようなJavascriptとCSSを今く涩妥があり, 钳琐にコ〖ディングしましたが, 赖しく瓢くまでかなり络恃でした。(塑喀のwebデザイナ〖の数であれば, このくらいは途偷なのだと蛔いますが..。)
柒婶ではPythonのPDFminerでPDFをテキスト步して豺老していますが, PDFによっては己窃することがあるため, その眷圭はそれを极瓢弄に浮叫してPyPDFの数で借妄する, というような慌寥みになっています。PDFを豺老した冯蔡, 布淡の数恕で纷换されるその侠矢の琵纷弄なキ〖ワ〖ドが山绩されるため, その罢蹋でも冯菇烫球いと蛔います(宝の茶咙)。
さらに, 帽に甫垫荚の叹涟が山绩されるだけではどんな客かが尸からないため, 徒め甫垫荚を山すキ〖ワ〖ドを琵纷弄に纷换しておき, 惧淡の茶咙のようにそれを山绩するようにしました。
これは, 称甫垫荚ベクトルから徒鳞される帽胳澄唯のNPMI (Normalized PMI)の惧疤を山绩したものです。
恶挛弄には, 甫垫荚 a が帽胳 w を叫蜗する澄唯 p(w|a) はモデルから滇めることができますが, これをwの士堆弄な澄唯と孺秤して滦眶をとった log p(w|a)/p(w) は甫垫荚aと帽胳wの极甘陵高攫鼠翁(PMI)を山しています。ただしこれは, wの澄唯p(w)が井さいと册梢に瓤炳するため, PMIの呵络猛である -log p(w,a) との孺をとったNPMIを脱いるのが努しています。
海の眷圭, wとaが窗链に陵簇していれば, p(w,a)=p(w)=p(a)なので, NPMIは
NPMI(w,a) = - (log p(w|a)/p(w)) / (log p(w))で滇めることができます。
悸狠に纷换してみると, これは甫垫荚の泼魔をかなり赖澄に山しており, 润撅に烫球い攫鼠になりました。ACL anthologyに5塑笆惧侠矢がある甫垫荚8963客の琵纷弄なNPMIキ〖ワ〖ドを纷换したものが
こちら
です。(侠矢眶の驴い界)
これは, 极脸咐胳借妄の甫垫荚にとっては, いくら斧ていても税きないほどの攫鼠な丹がします。たとえば揪塑黎栏やグラムさんのNPMIキ〖ワ〖ドは
Yuji Matsumoto japanese, method, dependency, word, pos, proposed, corpus, because, parsing, words Graham Neubig translation, bleu, nmt, languages, decoder, language, source, training, model, resourceとなっており, 澄かにそういう丹がします。 铜叹疥では毋えば
Dan Klein parsing, manning, petrov, parse, over, likelihood, collins, substantially, penn, model Kathleen McKeown summarization, summary, summaries, generation, views, sentences, content, sentence, document, produce Mark Steedman ccg, categorial, combinatory, parser, category, parsing, derivations, np, categories, derivationで, これも润撅に屡碰な冯蔡に蛔えます。 なお, 讳极咳のキ〖ワ〖ドは
Daichi Mochihashi bayesian, gram, probability, japanese, sampling, segmentation, dirichlet, distribution, gibbs, wで, ACL废の侠矢に嘎ってみれば澄かにそうだろうなと蛔います。 悸狠には讳はロボティクスなど戮の尸填の侠矢も叫しているので, もし链挛のデ〖タセットで纷换できたとすると, もう警し琵纷弄なキ〖ワ〖ドは恃わるのではないかと蛔います。
なお, ACL2Vec-authorsと票屯な甫垫荚夸力システムは, 讳が尸老甫垫镑を坛める泣塑池窖慷督柴の池窖攫鼠尸老センタ〖ですでに苍漂していますが, キ〖ワ〖ドや侠矢PDFに答づいて瓢弄に夸力を乖うシステムの悸刘は, 海搀が介めてとなります。