| 先月 |
2008年07月 |
来月 |
| 日 |
月 |
火 |
水 |
木 |
金 |
土 |
| |
1 |
2 |
3 |
4 |
5 |
| 6 |
7 |
8 |
9 |
10 |
11 |
12 |
| 13 |
14 |
15 |
16 |
17 |
18 |
19 |
| 20 |
21 |
22 |
23 |
24 |
25 |
26 |
| 27 |
28 |
29 |
30 |
31 |
|
|
|
|
#1
PRML日本語版 下巻発売
PRML日本語版
の下巻
[amazon]
が7/8(amazonでは7/11になっている)に発売だそうで, ちょうど
訳者謹呈本が届きました。
amazonで予約受付け中だそうです。

下巻はカーネル法, グラフィカルモデル, MCMC, EM, 変分ベイズ法, 確率的主成分分析
その他と内容が豪華で, すごく「実用的」な感じです。
僕が担当したのは10章の変分ベイズ法とEPでした。
翻訳した後で気づいたのですが, 10章は中でも Bishop 自身の専門でもある
こともあって, かなり内容が複雑です。
そのため, 補助動詞にひらがなを意識的に使ったり, リズムを持って読めるように
訳を色々工夫してわかりやすくしたのですが,
*1
それでも結構複雑なのと, 変分ベイズの一般的な公式が十分抽象的な
形で示されていないので, 変分ベイズ法について知りたい方は, まず最初に前に書いた
"自然言語処理のための変分ベイズ法"
などのスライドか参考文献に上げた論文
を読んで一般論を理解してから,
ガウス分布の場合や線形回帰についての適用などについて知りたい
場合に, PRMLの方を読むといいのではないかと思います。
神嶌さんのリーダーシップで, これで上下巻が揃って, 上巻はかなり
売れているそうです。
個人的には, 黄色-赤系統のSpringerの表紙に帯が青文字の下巻はかなりいいなと
思ったので, 上巻の帯も赤ではなく, 緑文字にするといいような気がします。
*2
*1: 私用で先に原稿を読まれた井手さんに, 訳を褒めていただきました。
恥ずかしいですね.. ^^;。
*2: 青が先端的なイメージであるのに対して, 緑は基礎的なイメージがするということも
あります。
#2
CS研異動
7/1付けで, 中岩さんと交代で上田さんがCS研の
副所長に。
(外挿すると..という話も。)
上田さんは4Fの企画に行ってしまったのですが, それでも時々3Fに来て研究されて
いるようで, 凄いなと思います。
#1
Bayesian Domain Adaptation
ちょうど今やっているICML 2008のワークショップ,
NPBayes 2008
(招待されていたし超行きたかったのですが, 行けなかった..;)と
Prior knowledge for Text and Language
の論文の概要が読めるようになっていたため, 読んでみたのでこの場でいくつか
整理。
Frank Woodの
"A Hierarchical, Hierarchical Pitman Yor Process Language Model"
(2pages)は階層ベイズ言語モデルの分野適応を行うという話。
少量の分野コーパスと大量の一般コーパス(新聞等)があったとき, よくある方法は
それぞれで学習した言語モデルを線形補間したり, 単語のカウントを混ぜたり
するというヒューリスティックな方法。
これに対して, この話ではカウントが生まれる base measure=バックオフ分布が
上手い混合分布になるというモデルを使っている。具体的には,
c(w|h) ~ PY(d,θ,πGD(h')+(1-π)G0(h))
という形で, 文脈hの後での単語wのカウントc(w|h)が生まれたとする。
ここでdとθはPitman-Yor過程 PY(d,θ,G)のパラメータで,
添字Dと0はそれぞれ, 対象ドメインのデータと一般データを用いた言語モデルでの
base measure。h'は1つオーダーを落とした文脈(trigram->bigramなど)を表す。
つまりこれは, 文脈 h の後の単語 w は
- c(w|h)がすでに存在するなら, c(w|h)-d に比例した確率で選ばれる
- c(w|h)が存在しないなら,
- 確率πで, そのドメインの1つ長さの短い文脈から生成される, or
- 確率(1-π)で, 全体ドメインの文脈から生成される
ということ。
*1
具体的には, 医学テキストでの「血管 結紮」に続く「操作」は
「術」のようにカウントが存在しなければ,
確率πで医学分野の「結紮 操作」の単語繋がりから生成されるか,
確率(1-π)で一般新聞記事での「血管 結紮 操作」の繋がりから生成される
(この場合は多分前者が正しい), ということ。
このモデルに対してGibbsを構成して推論が可能とのこと。
通常のように確率を適当に線形補間する方法と違うのは, カウントがなかった場合のみ,
バックオフ部分で混合が起こるということ。当然実験での性能は高いらしい。
ただしこの方法は, トピックが既知で, 一般とそれ以外の2個しかない状況を対象と
しているので, VPYLDAでやってみたように, 完全に教師なしでトピック言語モデルを
作る場合にどうするかは書かれていない。
*1: このπが文脈毎に違う値を取れるのかどうかは, 論文からはわからない。
#2
Bayesian Dependency Analysis
もう一つは, Hanna Wallach の
"Bayesian Modeling of Dependency Trees Using Hierarchical Pitman-Yor Priors".
これは++を付けていたのに, 僕には回ってこなかったのですが(謎), これで内容が
読めるようになった。ちょっと論文での書き方がわかりにくいので, 以下で整理。
構文解析をノンパラメトリックベイズでやるというのは, Mark JohnsonのMCMC-PCFGや
LiangのHDP-PCFGと似ているのですが, ここでは依存構造解析なので, 完全に「語彙化」
されていて, 1段階のHDPでよいHDP-PCFG等と違ってスムージングが重要になる。
具体的には, 依存構造木 t が与えられたとき,
*2
文 w と形態素タグ系列 s, 大文字/小文字かの区別 c との同時確率が
p(w,s,c|t) = Πn p(s|s',s'',w',c',d)・p(w|s,w',s',c',d)・p(c|s,w)
で与えられるとする(添字のnは省略)。ここで w'や s'' はそれぞれ, 注目している単語の親(')および
兄弟('')の単語やそのタグ。
dは, 右に分かれるか左に分かれるか(direction)を表す。
これらの確率は6-gramと3-gramで非常にスパースであるため,
ここにPitman-Yor過程に従う
階層的なpriorを入れて情報を共有します, ということらしい。
具体的には, n を除いて書くと, それぞれの条件部を3段階まで, 次のような順番で
階層スムージングする。
(論文より下の方がわかりやすいはず)
| 1 | p(s|s',s'',w',c',d) | p(w|s,s',w',c',d) | p(c|s,w) |
|---|
| 2 | p(s|s',s'',d) | p(w|s,s',d) | p(c|s) |
|---|
| 3 | p(s|s',d) | p(w|s) | - |
|---|
このスムージングの方法は, 実はEisner(1996)の方法と同じで, Eisnerの方法は
Pitman-Yor過程の代わりにHDPを使って, かつconcentrationパラメータαをそれぞれ
定数にfixした場合に相当しているらしい。ベイズ的に考えるとこれらのαやdは
それぞれサンプリングして推定できるので,
実際に精度は80.7%(Eisner)→85.7%(Pitman-Yor)まで上がる。
個人的に面白かったのは, 依存構造解析はPCFGと違って語彙化されているので,
上の第2項の確率は, 状態 s からの単語 w の生成確率を表しており, 論文のTable 3
に表れているように, 形態素タグを未知にして学習させた場合に, 訓練データのタグ
と違って, 意味的/構文的に非常に興味深い単語クラスタリングが現れる,
ということ。
これは
HMM-LDA
(NIPS 2004)のものと似ているが, HMM-LDAと違って, 状態がTreeになっているという点
が異なる。(ただし, このWallachの論文では木構造自体は既知としている。)
ということで, 依存構造解析にもきちんと階層確率モデルを作ることができる
ということで, 面白かったなと。木を教師なしで学習するのが,
次の重要なステップな気がします。
*2: 論文では条件付きになっていないが, これは教師あり学習なので,
本当はそう書くべき。
#1
Google Sparse Hash <-> Splay Tree
前に日記で書いた,
自己組織化二分探索木であるSplay Treeは
struct splay {
splay *left;
splay *right;
void *item;
};
というデータ構造を持っているため, データ構造へのポインタのきっかり3倍の
記憶容量を必要とする。
順番は多くの場合関係ないので, こうした動的なデータ構造には本来ハッシュを
使えばいいはず
だが, 普通のハッシュでは不要なメモリが沢山確保される可能性があるため,
スプレー木を使っていた。
ハッシュテーブルが1つなら大した問題ではないですが, テーブル自体が何万個も
あったりすると, そのロスは膨大なものになります。
最近, 開発環境をCからC++に変えたため(理由はそのうち), Googleの提供している
Memory-efficientな
Google Sparse Hash
が使えるようになったので, 実行速度を比較してみた。
研究の都合上文字列の比較が必要になるため, 文字列関数の実行回数の少ない(と思われ
る)ハッシュを使うべきではないか, という予測もありました。
先に結果だけ書いておくと, スプレー木の圧勝でした。(!) 驚き。
空白で区切られた単語の出現回数を数える, スプレー木のCのコードは, 重要なところだけ
書くと
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "splay.h"
typedef struct {
char *string;
int count;
} entry;
int
entcmp (entry *a, entry *b)
{
return strcmp(a->string, b->string);
}
int
main (int argc, char *argv[])
{
splay *tree = NULL;
char s[BUFSIZ];
entry e, *ep;
FILE *fp;
// fp をオープン
while (read_word(fp, s) != EOF)
{
e.string = s;
if ((ep = splay_find(&tree, &e, (cmpfunc)entcmp)) == NULL)
{
if ((ep = (entry *)malloc(sizeof(entry))) == NULL)
{
perror("malloc");
exit(1);
} else {
ep->string = strdup(s);
ep->count = 1;
}
tree = splay_insert(tree, ep, (cmpfunc)entcmp);
} else {
ep->count++;
}
}
// splay_print (tree, (prfunc)entprint);
fclose(fp);
return 0;
}
のようになります。(速度比較のため, // で結果表示部をコメントアウト)
これに対して, 全く同じことをする Google Sparse Hash のコードは以下のような
感じ。別に変なことはしていないと思うのですが..。
#include <iostream>
#include <google/sparse_hash_map>
#include <cstdio>
#include <cstring>
using namespace std;
using namespace __gnu_cxx;
using google::sparse_hash_map;
struct eqstr
{
bool operator() (const char *a, const char *b) const
{
return (a == b) || (a && b && strcmp(a,b) == 0);
}
};
int
read_word (FILE *fp, const char *buf)
{
return fscanf(fp, "%s", buf);
}
int
main (int argc, char *argv[])
{
FILE *fp;
char s[BUFSIZ];
sparse_hash_map <const char *,int,hash<const char *>,eqstr> lexicon;
sparse_hash_map <const char *,int,hash<const char *>,eqstr>::iterator it;
if ((fp = fopen(argv[1], "r")) == NULL)
{
perror("fopen");
exit(1);
}
while (read_word(fp, s) != EOF)
{
if ((it = lexicon.find(s)) == lexicon.end())
{
lexicon[strdup(s)] = 1;
} else {
it->second++; // count++;
}
}
fclose(fp);
// for (it = lexicon.begin(); it != lexicon.end(); it++)
// {
// printf("%s\t%d\n", it->first, it->second);
// }
return 0;
}
実際には sparse_hash_map は
ドキュメント
によると, メモリ最適化を優先しているため, 速度優先のためには
dense_hash_map
を使うべきらしい(こちらの方が相当高速だが, メモリ使用量は増える)。
コードは上のものを dense_hash_map に変えたもの+1行だけなので省略。
以上のプログラムを, テキストの単語の出現回数を数える場合で比較してみた。
テキストは毎日新聞2001年度全文から1000000行(約2/3ぐらい)。
最後に比較のため, awkワンライナーで同じことをした場合の結果も載せておきます。
| algorithm | time | memory |
|---|
| splay tree | 17.2s | 7588K |
| ext/hash_map | 11.4s | 7544K |
| dense_hash_map | 147.8s | 6972K |
| sparse_hash_map | 505.5s | 6152K |
| (awk) | 15.4s | 17380K |
実際, Google Sparse Hash の方が高性能かと思っていたので, 意外でした。
ただし, メモリ量で見ると若干 sparse hash の方が勝っているようです。
*1
こんなに差が出たのは, 言語の場合は単語頻度に強烈なPower lawがあって,
「が」や「も」のような機能語が何度も何度も検索されるため, それらが自動的に木の
上に集まって高速にアクセスされるスプレー木が勝った, ということではないか..と
思ったのですが, 1..1000000までの数字がランダムに1回ずつ現れるテキストで
実験したところ,
splay tree(5.4s), dense_hash_map(158.1s), sparse_hash_map(367s)とやはり差は
大きかったので, 細かいところまで自分で面倒を見るCのコードの方が高速, ということ
なのかもしれません。それにしても大きすぎる違いだ..。
*2
というわけで, ∞-gramの実装にハッシュを使わず, スプレー木にしたのは結局正解
だったようです。うーん。
*1: この記憶量のうち, 文字列の確保に必要なメモリは314kbytesくらいなので,
大部分はアルゴリズムの差であることがわかる。
*2: コンピュータサイエンス的に言うと, 同値かどうかだけを問題にするハッシュは,
比較関数から本来得られる <, > という情報を落としているので, その分効率が落ちて
いるのかもしれません。
 追記:
追記:
坪坂君の追試のエントリ
によると, 上の性能の違いは, __gnu_cxx の文字列のデフォルトのハッシュ関数の性能
が非常に悪いから, だそうです。
#1
Windows XP+Mac
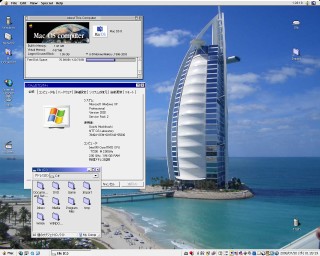
注: 以下の話は研究には関係ありません。
MacをやめてWindowsを(家で)使い出した時から,
エクスプローラにいちいち「ファイル(F) 編集(E)..」というメニューとWindowsロゴが
付くのが
うるさいと思っていたが, どうやっても消すことができなかった。
最近になって,
HMB2
というフリーソフトを使うと, これを消すことができるのを知りました。ブラボー。
HMB2はもう公式ページがないようですが, 上のリンクから取ることができます。
新規フォルダを作ったりしたい場合は, フォルダの何もない所を右クリックすれば
普通に行うことができて, 意味を考えると, その方が自然な気もします。
もし必要な場合は, タスクバーのHMB2アイコンをクリックすれば, メニューバーの
表示/非表示を切り換えることができます。
いつものように
「窓の手」
でシステムのアイコンを変更したり,
エクスプローラの「デザイン」で色をMacintoshのPlatinum色
*1
に代えたりしたものが上の画像(クリックで拡大)。
どうみてもMacです。本当にありがとうございました。
デスクトップのデザインを変更するにはStylerやWindowBlinds etc.の色々な
ソフトがありますが, 上の特徴は, そうしたものを一切使っていないということ。
それ系のソフトは無理矢理外観を変更しているので,
経験的にシステムが不安定になったり, ちょっとしたことでデフォルトのデザインが
現れて「化けの皮が剥がれる」
*2
ことがよくありますが,
上ではシステムの標準に従って変えているだけなので,
そういうことは全く起こらないというメリットがあります。
実はこれはハード的には Mac Mini だったりするので(w, BootCampで設定を変えれば
本物のOSXが立ち上がるわけですが, 色々な意味でWindowsの方が,
ソフトが多いために便利なことが多いような気がします。
個人的にはOSXのインターフェースより, ピクセルを無駄にしないOS 7〜9のデザイン
の方が好きですが, 上の画像がデフォルトのWindowsとは違いまくっているように,
カスタマイズすればかなり使いやすくなる..のかもしれません。
*1: 3DオブジェクトをRGB 239,239,239, ウインドウ内部を228,228,228にする
(自分用メモ).
*2: たとえば, Windows版のiTunesはウインドウを無理矢理Mac風にしていますが,
ちょっとしたことで「素の」Windowsのタイトルバーが表れてげんなりすることが
結構あります。
4 days displayed.
タイトル一覧
|  |
