 ACL2Vec
ACL2Vec
by Daichi Mochihashi, The Institute of Statistical Mathematics, Tokyo, Japan.
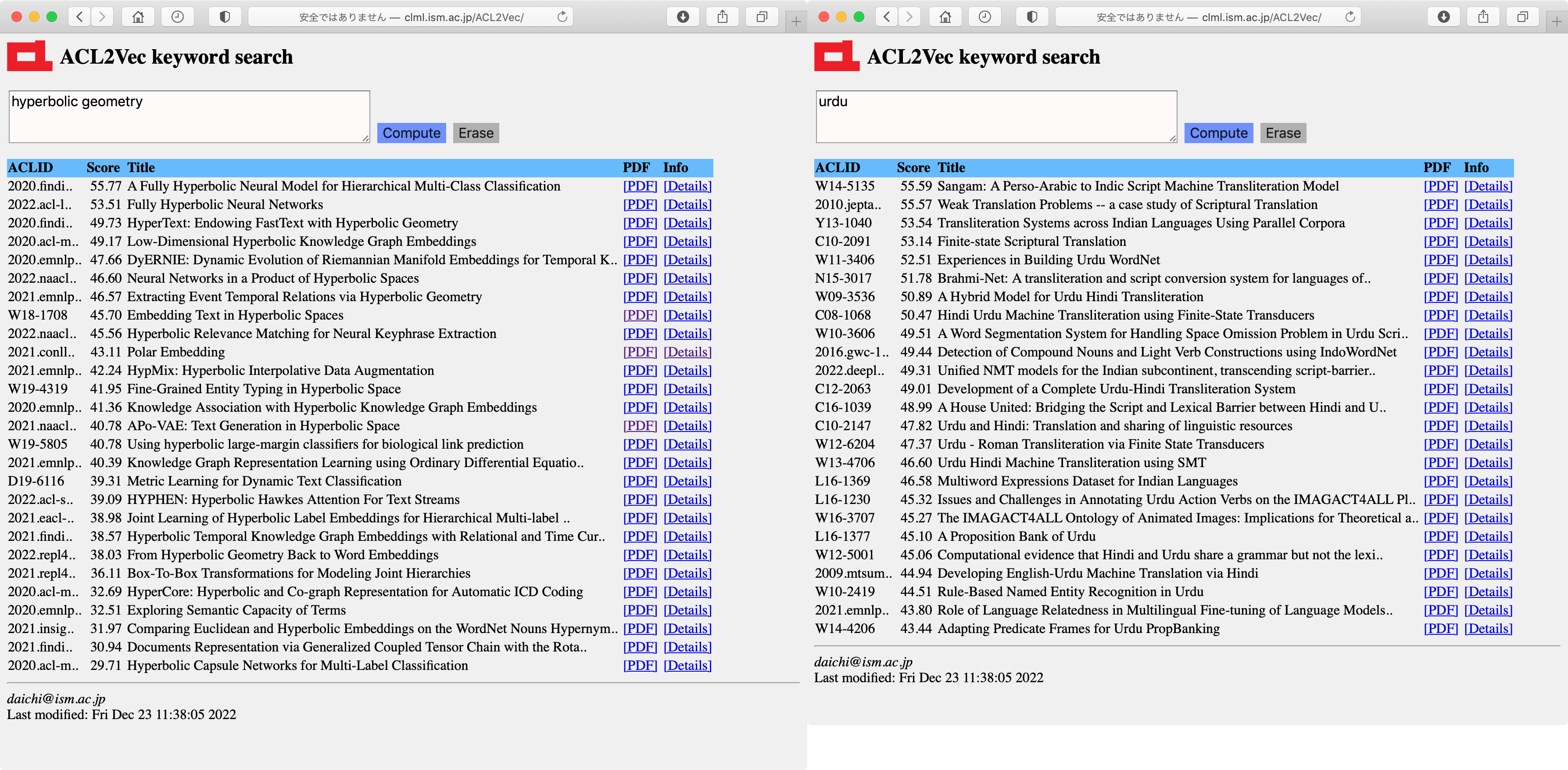
ACL2Vec,
ACL2Vec-authors are
neural search engines of natural language processing papers using the
New ACL Anthology Corpus on Github by Shaurya Rohatgi.
It originally contains 80,013 *ACL papers but after removing papers with
no authors, PDF conversion errors and too short content,
the system is built on 62,313 ACL papers up to September 2022.
Missing papers
Due to the quality of original data, 7,604 ACL papers (about 5%) are missing
from this system.
Don't worry about them: in fact, 4,328 papers (57%) of them are LREC papers (L),
and there are very few missing papers of
ACL(P), EMNLP(D), or NAACL(N).
The followings are the statistics of the currently missing papers.
ACL researcher's keywords
is a list of keywords computed for each of 8,963 researchers who have >= 5 papers
in ACL anthology.
These keywords are statistically computed by normalized PMI (NPMI), and largely
represent "what words are most associated with him/her" in the actual content of
ACL anthology papers. Note that there are no human intervention in creating these
statistical keywords.
Resources
Below are some statistics computed from the corpus.
Hope you find these resources interesting!
- ACL-titles.txt
is a list of 62,313 ACL papers (~2022) sorted by title.
- ACL-citations.txt
is a list of 62,313 ACL papers (~2022) sorted by the number of citations
(according to the dataset). Among them, 4166 papers (6.7%) have citations >= 100.
- ACL-authors.txt
is a list of 8,963 authors who have >= 5 papers in this dataset, sorted by the
number of publications.
- two-words.txt
is a list of papers that have only
two words as a title (like "LSTM Hypertagging").
Edited to remove possible errors.
- three-words.txt
is a list of papers that have only
three words as a title (like "Beyond Word N-Grams").
Edited to remove possible errors.
daichi
Last modified: Sun Jan 8 01:02:26 2023