| 先月 |
2006年12月 |
来月 |
| 日 |
月 |
火 |
水 |
木 |
金 |
土 |
| | | | |
1 |
2 |
| 3 |
4 |
5 |
6 |
7 |
8 |
9 |
| 10 |
11 |
12 |
13 |
14 |
15 |
16 |
| 17 |
18 |
19 |
20 |
21 |
22 |
23 |
| 24 |
25 |
26 |
27 |
28 |
29 |
30 |
| 31 |
|
|
|
|
#1
Natural Order in Unix

モデルなどの名前に "model.9" "model.10" .. などと数字を付けることは
クラスタリング等でよくあると思いますが,
この間IWSLT関係の仕事で, "model.0"〜"model.19" という名前がついたファイルを,
それぞれ "model.1"〜"model.20" にリネームする必要があった。
こういう複雑なリネームには, Camel Book のP.426にあるperlの万能スクリプト
rename を使って
for f in model.*; do
rename 's/\.(\d+)$/".".($1+1)/e' $f
done
とすればいいですが(マニアック!), 実は上のファイル名グロブ "model.*" は普通は
文字列としてソートされるため,
"model.1" "model.10" "model.11" .. "model.2" のように展開されてしまうので,
上ではうまく行かない(ファイルがどれか失くなってしまう)。
Unixの "sort -n" は名前が全て数字の場合にはうまく働くが, 上の場合のように
文字列と混合されている場合には働かない。
ごく一般的に, 数字を含んだファイル名を数値の部分を考慮して並べたいことは
よくあると思いますが,
Macintosh System7 には数字を含んだ文字列を「自然に」ソートする
ための Stuart Cheshire 氏による"Natural Order" という素晴らしいINITが1994年頃
からあって (上の画像),
機能拡張フォルダに入れておくだけで, システムの文字列比較関数を書き換えて,
Finder等のファイルが期待した通りに並ぶようになる。
[Natural Order Numerical Sorting]
これには上の画像にあるようにソースが付いているので, 前からやろうと思っていた
通り, 週末にちょっと工作して Unix で使えるようにしよう.. と思って
少し調べたら, すでに誰かがやっていた;。まあ確かに, ごく自然に
考えつきそうなことではあるけれども..。
[Natural Order String Comparison]
by Martin Pool 氏。
このページには perl, C, Haskell, Ruby, Python, Java, Javascript による実装例
が載っていて, GNU ls では, "--sort=version" を指定すると常に natural order
ソートになるらしい。確認したところ, 確かにそうなる模様。
ただ, 上のファイル名グロブはシェルが行うものなので, 後は zsh にパッチを当てれば
いいかな.. と思って下調べをしたら, これもすでにオプションが存在していた。
ガーン。;;
setopt numericglobsort
としておくと, 最初の例のようなファイル名展開が
"model.1" "model.2" .. "model.10" のように「自然な」順番になる模様。
これはX68000版の zsh のマニュアルに含まれる zshintro.jp に書いてあるので
読んでいたはずなのだが, 何となく見落としていたらしい。(;_;)
Stuart Cheshire 氏の「Natural Order」は1994年で, Martin Pool氏のページは
2000年くらいに独立に作ったページのようですが, zsh には1994年の時点で既に
numericglobsort のオプションは組み込まれていたようなので, zsh ユーザの慧眼に
改めて驚いた。
というわけで, まとめると
- ls には, 常に "--sort=version" オプションをつけて使う
- zsh ユーザなら, "setopt numericglobsort" を ~/.zshrc に書いておく
- それ以外の場合は, 上のページを参考に Natural order sort を行う "nsort" のようなコマンドを簡単に作っておく
*1
という手順で, Unix でも "Natural Order" によるソートを使うことができるようです。
*1: 上のページには GNU textutils の sort(1) に対するパッチもあるようですが,
今は sort(1) は GNU coreutils に含まれていて, アップデートの度に
毎回パッチを追従させるのは手間なので,
自分で別コマンドにして用意しておくとよさそうです。
#1
debug
Cのプログラムでこれまではデバッグ情報を普通にstderrに書いていたが,
そうするとプログラムの出力と混じってしまう上, 後から検証するのも難しくなる。
ふと気がついて, 下のような dprintf() 関数を書いて, 便利に使っている。
/*
debug.c
$Id: debug.c,v 1.3 2006/12/07 09:46:58 dmochiha Exp $
*/
#include <stdio.h>
#include <stdlib.h>
#include <stdarg.h>
#include "debug.h"
#define DEBUG_FILE "log.debug"
static FILE *dp = NULL;
int
dprintf (const char *fmt, ...)
{
int n;
va_list ap;
if (dp == NULL)
{
if ((dp = fopen(DEBUG_FILE, "w")) == NULL)
{
fprintf(stderr, "dprintf: can't open debugging output: %s\n",
DEBUG_FILE);
exit(1);
}
}
va_start(ap, fmt);
n = vfprintf(dp, fmt, ap);
fflush(dp);
va_end(ap);
return n;
}
何も考えず, 普通に
dprintf("table[%d] = %g\n", i, table[i]);
のようにすると, 固定ファイル(上では "log.debug")に結果が蓄積される。
必要なら, #ifdef DEBUG .. #endif で囲ってもいいかも。
この結果は途中で tail -f で見ることができるし(そのために上ではfflush()
している), 結果も残るので, 後から検証するのにも便利。
プログラムの出力と混ざらないので, 実験がとてもしやすくなった。
*1
可変長引数を取るのは Lisp では常識に近いのに, C言語の普通の講座では
ほとんど採り上げられていないような気がする。
最初にC言語を習った時に気になって
聞いたら, vararg.h を使えと言われたが, その当時はよくわからなくて使えなかった。
上は簡単な例ですが, 今頃になって大分わかってきたような気もする。
*1: 上でdpをクローズしていないのはわざとで, debug_finish()などを一々
実行しなくてすむようにするためです。
#1
SiliconGraphics 1600SW
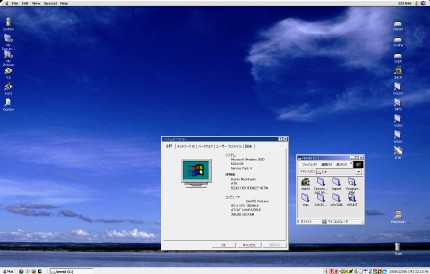
注: 以下の話は, 研究とは全然関係ありません。
最近ついに, 憧れのSGIの液晶モニタ, SiliconGraphics 1600SW
(こんなの)
を入手して, 使ってみた。
これは僕がまだNAISTのM2くらいだった頃(1999年くらい)に出たもので,
圧倒的なデザインと, 800x600くらいが普通にあった当時としては画期的に
広い, 1600x1024 の解像度を持っている。(上の画像)
*1
僕は発表されてすぐに知ったが, あまりに高価で(確か, 日本円で50万円くらい),
その後価格改訂がされて371,000円に
なったらしい
が, やっぱり高すぎて買えなかったもの。
オークションで出ていたので, 数万円で手に入れることができた。
僕は的儲
*2
なのですが, このために, DVI端子のある GeForce6200 のファンレスカード
Aeolus 6200-DV128LP AGP
を購入してついに乗り換えた。
実は, この1600SWはDVI端子ではなく, LDI規格という別のコネクタ
*3
でないと繋がらない。このためにSGIが出している変換器も同時に入手したのだが,
うっかりデジタルにアナログ入力を入れてしまったせいか壊れてしまった。;
(ていうか, そんなに簡単に壊れる機械ってどうよ, という気も..。)
仕方がないので, ドイツの
PIXsolution社
から出ている, 1600SW専用の変換器 PIX-Link 1600SW を個人輸入で購入。
*4
250€だったので, 日本円で約4万円くらい。少し前にFedexで届いたので, これでやっと
1600SWが使えるようになった。
さて, 使ってみると, 上の画像でわかる通り, とにかく横が広い。
横1600pixelというのは今となっては当たり前に近いですが, 7年前にこの解像度
を持っていたのは, 確かに驚嘆すべきものがあると思う。
ただ, これだけの画素を, 普通の17インチモニタ(+横幅拡張)の大きさに詰め込んで
いるため, とにかく文字が滅茶滅茶小さい。
Unixでは漢字の表示にはk14を使うのが普通なので, IRIXだと普通に使えると思うが,
Windowsでは目が疲れまくってしまった。;
また, 応答速度が40msと, 今となってはやや遅いので残像が気になる点と,
思ったほど色のコントラストが高くないという点も気になるところ。
ただ, 僕は中古で手に入れたので, 新品だと評判通り, (少なくとも当時としては)
圧倒的な画質を持っていたのかも知れない。
というわけで, 手に入れたものの常用するのは難しそうですが, NAISTの頃からの憧れの
1600SWを入手して使えたので, もうそれで充分満足なのだった。
*1: 一見どうみてもMacですが, これは僕のWindows2000です。(笑
*2: 「Matrox信者」
*3: VHSに対するβみたいなものらしい。
*4: この会社はページの下の方を見ると, もともとAmigaのカードを作っていた会社
らしい。少しマニアックかも。
#1
Splay Tree
研究上必要があって, 前々からずっと気になっていた, SleatorとTarjanの
スプレー木(Splay Tree)
[LINK]
を実装した。
スプレー木は「自己調整(自己組織化)二分木」ともいわれる通り,
頻度の高いアイテムをアクセスの際に木の上の方に自動的に持ってくることで,
高頻度なアイテムへの高速なアクセスを実現する順序木。
自然言語の文字列や単語列の頻度は偏りや Power law の固まりなので, 非常に適している
と思う。
かつ, 最悪の場合でもスプレー木は
全体を通して, O(log n) のアクセスを提供することがわかっている。
トライを表現するデータ構造としては, 松本研的には Double Array や
その実装である
Darts
がすぐ思い浮かぶと思いますが, Double Array は既に固定されたトライには高速にアクセス
できるものの, 新しいノードの追加や削除が超遅い
(単純な線形サーチより遅い)
*1
ので, 動的なデータ構造としては向いていない。
AVL木のようなアルゴリズムの授業でよく出てくる平衡木と違い, ノードに余分な
データを持たせる必要がなく, かつデータの挿入/検索に伴って自動的に
データ構造が調整されて高速なアクセスができる二分木になっている。
例によって, この手の話は中身をちゃんと理解しないと使えないわけですが,
日本語だと, M.Hiroi さんが今年になって
解説
を書かれているようで, とても参考になります。ただ, これだけではわからない部分が
多いので,
原論文
を読むとすっきりと理解できると思います。
3日くらい, 計算用紙に二分木を書きまくって, ようやく大体わかってきた。
スプレー木の基本は, アクセスしたノードを木の回転操作によってルートに持ってくる
"move to root" 操作。ただこの際に, ただ順番に木を回転すると, 木のバランス
が悪くなってしまい, O(log n)でなくなってしまう。
極端な例として, 木Δの左下端の
ノードを回転で根に持ってくると, 根の左側はNULLになり, 木の高さが1増えてしまう。
これを避けるために, 上のような木の"稜線"に沿ったアクセスの場合には, 先に上の
ノードを回転し(雰囲気的に言うと, 木をそこで山折りに折り直して),
その後で自分のノードを回転する(splay 操作)。
こうすることで, 木が平衡状態に常に近く保たれる。
アクセスされたノードはこの操作で上に集まるので, 二分順序木の中で,
頻度の高いノードは自然に上の方に, 頻度の低いノードは下の方に集まることになる。
上のページ
に, splay 操作のデモがあります。
実装としては,
Sleator が提供しているもの
があってそれで充分なのですが, このサンプルコードは int の二分木だけなので,
void * の一般的なデータを挿入できるように一般化してみました。
最終版ではないですし, 需要があるかどうかわかりませんが, 下に置いておきます。
splay.c
splay.h
C++ならテンプレートで何とかする所だと思いますが, シンプルにCでする場合は,
qsort と同じように, ノードを比較する関数へのポインタを与えて
splay *tree = NULL;
for (i = 1; i < argc; i++)
tree = splay_insert(tree, argv[i], (cmpfunc)strcmp);
として使えるようになっています (上は文字列を挿入する例)。
さてそうすると, 実際に言語のデータを与えた時, どんな二分木ができるのかが
気になるところ。
上の splay.c を使って, 下のようなプログラムを書くと,
% gcc -c splay.c
% gcc -o sptest sptest.c splay.o
% ./sptest [text]
で, スペースで区切られたテキストの単語を次々に木に挿入して(この時, 自動的に
木が調整される), 最後にスプレー木が出力される。
/*
sptest.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "splay.h"
int
read_word (FILE *fp, char *buf)
{
return fscanf(fp, "%s", buf);
}
int
main (int argc, char *argv[])
{
splay *tree = NULL;
char s[BUFSIZ];
FILE *fp;
if ((fp = fopen(argv[1], "r")) == NULL)
{
perror("fopen");
exit(1);
}
while (read_word(fp, s) != EOF)
{
if (splay_find(&tree, s, (cmpfunc)strcmp) == NULL)
tree = splay_insert(tree, strdup(s), (cmpfunc)strcmp);
}
splay_print(tree, (prfunc)puts);
fclose(fp);
return 0;
}
上のプログラムを使って,
"Alice in Wonderland" の全文(約3600行)と, 毎日新聞2000年度の全テキスト
(約150万行, 高頻度20000語)から構築したスプレー木が以下。
alice-tree.txt
mai-tree.txt
splay_print() の定義をよく読むとわかると思いますが
(M.Hiroiさんのプログラムからお借りしました), この木は左が上で,
頭を90°左に回転させて読みます。
*2
順序二分木なので, 単語は上から下に順にソートされていますが,
頻度の高い単語が見事に左の方(つまり, 木の上の方)に集まっていることがわかって,
面白い。
*1: 最近は少し改善されているかも知れませんが, 基本的に固定されたトライへの
アクセスを提供するという部分は, 多分変わっていないと思う。
*2: "Alice" の方は "end" が根になっていますが, これはスプレー木が
最後にアクセスしたアイテムをルートに持ってくるためで, テキストの最後が
end で終わっているからです。
上のデータでは,
- alice-tree.txt : 総語彙 = 26406 木の深さ = 33 (MAX)
- mai-tree.txt : 総語彙 = 20000 木の深さ = 36 (MAX)
になっています。
ここで, 構築されたスプレー木を使ってテキストを読み直して, アクセスされた
単語ノードの深さの平均を計算してみたところ,
- alice-tree.txt : 12.13
- mai-tree.txt : 13.39
でした。
log
2(26406)=14.7, log
2(20000)=14.3なので, つまり, 動的に構築した
このスプレー木は最深部が深さ33-36と充分大きいにもかかわらず, 完全二分木より
さらに性能が良くなっているということ。
*3
log を取っているのでそれほど違いがないように見えますが,
このスプレー木の"パープレキシティ"を計算すると, それぞれ
2^12.13 = 4502, 2^13.39 = 10774 になって, それぞれ実効語彙数が4500, 10000程度の
完全二分木と同等になっている。
データを読みながら, 動的に完全二分木を作ることは非常に難しいことを
考えると, 動的に作っているにも関わらず, 言語の性質を利用して
完全二分木よりもさらに良い性能を出しているというのは素晴らしいと思う。
上の平均の計算はスプレー木を固定して行いましたが,
スプレー木はアクセスする毎に splay 操作が起こってノードが根に来るため, 一種の
「キャッシュ」が掛かるので, 実際の性能はさらに高くなっている可能性がある
と思う。
*3: 内部節点を使わない二分探索の場合。
内部節点も使う場合は, もう少し数値が違ってくると思う。
 Acknowledgement
Acknowledgement
実装に際して, エンジニアのF澤さんにアドバイスをいただきました。
感謝します。
4 days displayed.
タイトル一覧
|  |