#1
smoothed DM
このNLP2006前の時期に.. という感じですが, Reversing EM を実装した
DM の階層ベイズ版を dm-0.2.tar.gz として
公開
しました。
単に自分が使うからという話もありますが(^^;), 公開するようにしないと
細かい部分を詰める気が起こらないので, という理由だったりします。
以下は cranfield についての例です。(コマンドの名前は sdm になっています。)
~/work/sdm/src% ./sdm -h
sdm, hierarchically smoothed Dirichlet Mixtures.
Copyright (C) 2006 Daichi Mochihashi, all rights reserved.
$Id: sdm.c,v 1.2 2006/02/02 16:28:51 dmochiha Exp $
usage: sdm -M mixtures [-I emmax] [-R remmax] [-E epsilon] train model
~/work/sdm/src% ./sdm cran.dat cran.model
number of documents = 1397
number of words = 5177
number of mixtures = 50
convergence criterion = 0.01 %
iteration 3/50 [REM 2+16]... PPL = 258.464 ETA: 0:36:00 (45 sec/step)
converged. [ 0:01:43]
writing model..
done.
外側のEMではハイパーパラメータだけを最適化しているので3回しか回って
いませんが, 実際の最適化は内側の2+16=18回のReversing EMで行われて
います。cranfield だとかなり速いですが, 大きなコーパスだともっと時間が
かかります。
論文
を最初に読んだ時は式が複雑に見えてびっくりしましたが,
慣れてくると全然自明に見えてくるという罠。(もちろん, それを導くのは
全然自明ではないわけですが。)
MATLAB 作図テク集。(というかメモ。)
- 行列をそのまま視覚化するには, pcolor コマンドを使う。
- pcolor コマンドは, surf(); view([0 90]) と同じ。(真上から見ている)
- このままでは行列要素のグリッドが取れないが, surf() を使う上の方法で, surf(x,'EdgeColor','none'); view([0 90]); とやるとグリッドが取れる。
- 例えば colormap(gray(2)) とすると, 二値行列を白黒で表示できる。 このままでは白黒反転している場合があるので, gray(2) の出力が単純に
[0 0 0; 1 1 1] であることを利用して, colormap([1 1 1; 0 0 0]); とやると
白黒反転した色マップになる。
- MATLAB Figure ウインドウでいくら大きさを調整しても, Export して EPS に すると反映されない。(Unixの場合) File->Page Setup.. で
'Match Figure Screen Size' の方にチェックを入れておくと反映される。
参照:
印刷とエクスポート
#2
submit
1日遅れで言語処理学会の原稿を無事に?submit。
そもそも今回の言語処理学会大会に出そうと思ったのは, 何か出さないと
山本先生の言語モデルのチュートリアルが聞けないから, という理由だったり
したのだが, いつの間にか自分が講師の側になってしまっているので,
もう山本先生のスライド原稿を読みまくっていたりする。w
#1
recycler
「Unixでごみ箱の機能がほしいんですけど。」-> 「練習で、ごみ箱機能を実現する
シェルスクリプトを書いてみよう。」
というのは Unix 初心者によくある風景です。
慣れてくると rm -i も使わなくなって, ファイルは rm であっさり消す
ようになるわけですが, きちんとしたものがあれば便利そうなので,
何かごみ箱機能を実現する決定版のようなものは
ないのだろうか.. と前から思っていたら, NEXTSTEPの
リサイクラ
をコマンドラインから
アクセスするシェルスクリプトが
このページ
にあるのを見つけました。
中身も見てみましたが, とても素直に書かれています。
この /bin/sh のスクリプトは単に ~/.NeXT/.NextTrash/ にファイルを mv したり,
そこから mv したりしているだけなので, そこを書き替えれば Linux 等でも普通に
使えます。
環境変数 $TRASH が設定されていたらそれを使って,
なければ ~/.trash を必要なら作製して使う, というちょっとした変更をした
ものを下に置いておきました。OSXではごみ箱は ~/.Trash らしいので,
そう変更しておけばOSXでも使えると思います。
"rc" (recycle) がリサイクラに入れるコマンド, "rt" (retrieve) が
リサイクラから戻すコマンドです。rc も rt も少なくても有名なコマンドにはない
上, 短いので名前としても適切な気がします。
ちなみに, % rt file として $TRASH/file からカレントに戻す時,
そもそもリサイクラにどんなファイルがあるかわからないと難しいので,
~/.zshrc に 下のように書いておくと % rt [TAB] で補完が効きます。
下に置いたファイルでは, さらに % rt -l とするとリサイクラの中身が見れる
ようにしておきました。
_recycler () {
local trdir="${TRASH:-$HOME/.trash}"
reply=(`cd $trdir; echo *`)
}
compctl -K _recycler rt
[rc]
[rt]
 -
-
なお, ~/.zshrc でさらに trash=${TRASH:-~/.trash} としておくと,
% ls ~trash
total 8
-rwxr-xr-x 1 dmochiha slt 517 02-10 21:54 testrc*
% cp ~trash/testrc .
のようなことができます。
Linux には Solaris のように漢字コードを表示する kanji コマンドはないので,
漢字コードを知りたい時には不便だなぁ, と思っていたら,
単にEUCの漢字コード表を
たとえばこのへん
から持ってきて, ~/man/cat1/kanji.1 として保存しておけば,
% man kanji
で見れることに気づいた。便利すぎ。というか, どうして今まで
気がつかなかったのだろう。
同じようにして
jcode.pl のマニュアル
も jcode.1 としてcat1に置いておけば, % man jcode で jcode.pl のマニュアルが
見れる。一々Webを見なくてもいいので, 便利。
MANPATH は特に設定していないが, man --path を実行すると, デフォルトで
~/man は見るようになっている模様。
#1
Bayesian Sets
Bayesian Sets (Ghahramani and Heller, NIPS 2005)は
Google Sets
と同じようなことをベイズ的に行うアルゴリズムです。
いくつかアイテムを入れると, それを「補完する」ようなアイテムを
返してくれます。
これは NIPS の accepted papers が出た去年の8月から気になっていて,
本会議ではオーラルの発表もあって大体のやっていることはわかった
ものの, 何と(本会議の時も!)論文がなく, 直接Hellerに連絡して
もらえるように頼んでいたところ, Online proceedings の締切りがあった
時に連絡があって, 読めるようになりました。(リンクは下のページ参照)
岡野原君に先に
紹介
されてしまいましたが, 以下は, 岡野原君が書いていない話。
Bayesian Sets は, アイテム集合 D に対して,
クエリとしてそのサブセット
Dc ⊂ D が与えられた時に, 残りのアイテム x ∈ D を
Dc と同じクラスタに含まれると思われる順にソートして返すアルゴリズム。
ナイーブに考えるとこれは
p(x|Dc) を評価すればいいような感じがするが, x の大域的な確率 p(x)
が高ければ,
Dc にかかわらずこれは高い値を持ってしまう (言語だと,「が」や「の」のような
機能語が検索されてしまうことに相当する)。
*1
よって, 上のスコアを p(x) で割って
p(x|Dc) / p(x) (1)
を評価することにすれば, 頻度の影響を取り除くことができる。
さて, (1)式は実は
p(x|D
c) / p(x) = p(x,D
c) / p(x)p(D
c)と一緒なので, 実際にはこれの log を取ってスコアにすると,
I(x) = log p(x,Dc)/p(Dc)p(x) (2)
が
D
c が与えられた下でのx のスコアになって, これで検索するとうまくいくことがわかる。
これはどうみても(自己)相互情報量なので, 実はこれは集合についてたとえば
Church (1989)
"word association norms, mutual information, and lexicography"
と似たことをしている。しかし, 論文には相互情報量だとは
一言も書いていないのが不思議。
さて, Bayesian Sets のポイントは, 上の確率
p(x,Dc), p(Dc), p(x) を計算する時に最尤推定で求めるのではなく, vague な事前分布を与えて,
パラメータθを積分消去してしまうという点。結局, 上の I(x) はハイパーパラメータ
だけに依存する, Γ関数を沢山含んだ関数になるが, 素性がバイナリの場合は
Γ(x+1)=xΓ(x) の関係を使うとどんどん綺麗な形になって, 最終的に
I(x) は列がアイテム, 行がアイテムの持つ素性を表す二値疎行列(データ) X と,
クエリに依存する重みベクトル w との内積を計算することに帰着する。
*2
これをMATLABで簡単に実装してみたのが下のページです。
データとして
MovieLens
100Kを使って, 例えば「ピアノ・レッスン」
(←好きな映画らしい。)をクエリとして
検索してみた結果は以下。見事に音楽映画が上位に来ている
ことがわかる。
>> help bsets
s = bsets(X,q,alpha,beta)
Bayesian Sets (Ghahramani and Heller, 2005) implementation.
X : binary sparse matrix of (features * entries)
q : row vector of query indexes
s : row vector of scores for each entry in X
alpha,beta : Beta hyperparameters of prior distribution (column vectors)
$Id: bsets.m,v 1.2 2006/02/13 13:54:02 dmochiha Exp $
>> bsshow(bsets(M,[582],alpha,beta),'movie.txt');
loading movie.txt..
done.
582 225.244 Piano, The (1993)
191 57.4856 Amadeus (1984)
132 55.4172 Wizard of Oz, The (1939)
170 55.2144 Cinema Paradiso (1988)
462 55.0451 Like Water For Chocolate (Como agua para chocolate) (1992)
483 48.5138 Casablanca (1942)
509 48.2819 My Left Foot (1989)
70 46.7287 Four Weddings and a Funeral (1994)
86 45.5685 Remains of the Day, The (1993)
196 45.3046 Dead Poets Society (1989)
*1: これは伊藤君がカーネルを使って解いている問題と同じ。
*2: ちなみに
p(x,D_c)/p(D_c)p(x) ∝ p(x,D_c)/p(x) = p(D_c|x)
なのだが, これで計算してみると, なぜか簡単な形にならない模様。
#2
however..
というわけで結構面白いのだが, 実はクエリを増やすと,
あまりよくないことが起こる。
普通はクエリを増やすと, それだけ結果が絞れて精密になるはずなのだが,
>> bsshow(bsets(M,[582 191 132 143],alpha,beta),'movie.txt');
% 「アマデウス」「ピアノ・レッスン」「オズの魔法使い」「サウンド・オブ・ミュージック」で検索
loading movie.txt..
done.
191 493.445 Amadeus (1984)
132 410.556 Wizard of Oz, The (1939)
174 366.719 Raiders of the Lost Ark (1981)
*98 358.637 Silence of the Lambs, The (1991)
*318 340.908 Schindler's List (1993)
*172 321.592 Empire Strikes Back, The (1980)
*69 320.884 Forrest Gump (1994)
143 319.785 Sound of Music, The (1965)
357 316.532 One Flew Over the Cuckoo's Nest (1975)
483 313.525 Casablanca (1942)
*423 309.385 E.T. the Extra-Terrestrial (1982)
*64 299.934 Shawshank Redemption, The (1994)
*204 292.22 Back to the Future (1985)
173 285.095 Princess Bride, The (1987)
*168 280.25 Monty Python and the Holy Grail (1974)
196 277.245 Dead Poets Society (1989)
*28 276.291 Apollo 13 (1995)
496 270.269 It's a Wonderful Life (1946)
427 268.64 To Kill a Mockingbird (1962)
*50 263.816 Star Wars (1977)
'*' を付けた結果が, 明らかに間違っているエントリ。
クエリを増やすと一般にこういうことが起こって, 大域的に人気の高い映画が
(p(x)で正規化しているにもかかわらず)出てきてしまう。
これはどうしてかというと, 重みベクトルの作り方に依存している。
最初の例の重みベクトル w_0 と, 後の例の重みベクトル w をプロットしたものが
以下。
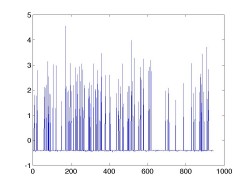 | 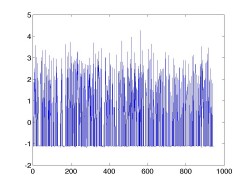 |
| w0: query = [582] | w: query = [582 191 132 143] |
「スターウォーズ」のような映画は多くの人が評価し, 素性として多くの1を
持っているので, この重みベクトルと内積を取った場合に, スコアがかなり高く
なってしまう。
この理由は、二つ考えることができる。重みベクトル w は,
各素性の持つ(バイナリなので)ベータ分布のハイパーパラメータ α, β
および, n 個の要素を持つクエリ(に対応するデータ行列の部分行列)中の素性の
カウント c を使って以下のように書けるが (論文では q と書かれている)
w = log(α+c) - log(β+n-c) - logα + logβ
これは, c = 0 の場合(素性はスパースなので, これがほとんど),
w = logβ - log(β+n)
に等しくなる。ここで, 一つでもクエリが素性を持っていて c = 1 になると,
w = log(α+1) - logα + logβ - log(β+n-1)
になる。
これは, 後半の第3項と第4項は c = 0 の場合とほとんど一緒
(1の差があるが, log を取っているのできわめて微妙にしか小さくならない)
なのに対し, αは「疎行列の中で各素性に1が立つ事前確率」なので通常かなり
小さい値であるため, 前半の
log(α+1) - logα = log(1 + 1/α) はかなり大きい値になって, この素性の重み
が一気に大きくなる。これを表しているのが上のグラフで, クエリの数が増える
ほど, 立っているスパイクの数が増えて, 1を多く持つエントリとの内積が大きく
なってしまう。(第4項のせいでスパイクの底が少し下がっているが,
スパイクの増え方に比べるとその影響はかなり小さい。)
この問題に対応するために, 論文の方ではデータを列に関して正規化する
ことが書かれているが, これはアドホックであるうえ, p(x) の影響を2回評価する
ことになるので, いい方法ではない。実際にやってみると, 行列を縦に正規化して
しまうと, ビットがほとんど立っていない, 非常に頻度が低いアイテムが上位に来て
しまい, 何も正規化しない方がまだよい結果を出すことがわかった。
もう一つ, この理由は十分統計量の作り方にも関連している。
Bayesian Sets では, 素性がクエリに対応するサブ行列の中で何回現れたか
という総和 c だけを使っているので, 例えばクエリに対応するサブ行列が
[1 1 1 0 0 0], [0 0 0 1 1 1] だった場合, 十分統計量はこの和として
[1 1 1 1 1 1] になってしまい, 直感的には 1 を多く持つエントリとの内積が
大きくなってしまう。これは, 素性空間上に一つの分布を仮定していることに
恐らく対応すると思うので, その平均が例え確率密度が薄くても, データを表現
していると解釈されてしまうという問題。
これは
2005/11/11
のIBISでの話と似たところがあって, 複雑な分布をきちんと表現するためには,
例えばカーネルで高次元に飛ばす, という方法もあるような気がする。
(Kernel Bayesian Sets?) これは単にそう思っただけなので, rigid な根拠が
あるわけではないけれども。
ということで, だいたい書きたいことを書いたので, NL研の話の方をやろうと
思います。
#1
Polygamma
注:以下の話はやたら細かいです。マニアック注意。
digamma関数 Ψ(x) = d/dxlogΓ(x)や, trigamma関数 Ψ'(x) = d^2/dx^2 logΓ(x)
などの polygamma 関数は, MATLAB では psi 関数が一般化されていて,
psi(n,x) で d^(n+1)/dx^(n+1) logΓ(x) を求めることができる。たとえば,
Ψ'(x) = psi(1,x).
C言語だと, digammaとtrigammaは
Lightspeed
の util.c に実装があるが, tetragamma関数 Ψ''(x) など,一般の polygamma 関数は
ないので, どうしようか, と思って探していたら,
石岡恒憲さんのページ
(一時期, 小論文の自動採点の話が有名になりましたが)に実装があるのを発見。
ガンマ関数の Newton 法に tetragamma 関数が必要になりそうで探していた
のですが, 結局僕の勘違い (trigammaまでしかいらなかった) だったので,
神! ということで紹介しておきます。
6 days displayed.
タイトル一覧
|  |
{kind=link}